
Ohne Traces, Modell- und Promptversionen, Tool-Spans und Kostenmetriken bleibt jeder Incident Spekulation.
Vier Posts lang habe ich über Prinzipien geschrieben: Contracts, Evals, Tool-Sicherheit, Human Oversight. Richtig - aber wie sehe ich im Betrieb, ob das alles tatsächlich funktioniert?
Ohne strukturierte Observability gar nicht. Ein False Success im Refund-Agent - das Tool meldet Erfolg, der Kunde wartet auf sein Geld - ist mit Application Logs und Error Rates nicht zu finden. Alles grün. Das System hat nicht versagt, es hat gelogen.
Dieser Post zeigt, welche Observability-Infrastruktur Teams brauchen, die AI-Features live betreiben. Welche Fragen muss ich beantworten können? Wie sieht ein guter Trace aus? Und wo ordne ich meinen eigenen Stand ein?

Fünf Fragen vor dem Tooling
Kurzer Rückblick: Der refund-agent begleitet uns als laufendes Beispiel durch die Serie - ein Multi-Agent Support-System, das Erstattungen verarbeitet. Das Szenario: Der Agent bestätigt dem Kunden, die Rückerstattung sei raus. War sie nicht. refund_order wurde nie erfolgreich ausgeführt, aber der Chatverlauf sah aus wie ein gelöstes Ticket. False Success.
Wie hätte ich das in 30 Sekunden debuggen können?
Nicht mit grep in Logfiles. Nicht mit einem Dashboard, das mir Uptime und Error Rate zeigt - denn beides war grün. Kein Fehler, kein Alert, nur ein falsches Ergebnis.
Traditionelle Metriken fangen AI-spezifische Fehler nicht ab. False Success, falsche Tool-Auswahl oder halluzinierte Aktionen bleiben unsichtbar, solange ich nur auf HTTP-Statuscodes und Exception-Counts schaue. Das Problem sitzt tiefer - in der Entscheidungslogik des Agents und in der Interpretation der Tool-Antworten. Zwischen Turns geht Kontext verloren, ohne dass irgendein Logfile darauf hinweist.
Bevor ich über Tooling rede, fünf Fragen, die jedes Team beantworten können sollte.
1. Debugging: Warum hat der Agent dem Kunden X gesagt, obwohl Y passiert ist?
Der Refund-Agent sagt “Erstattung ist raus”. Aber refund_order hat einen Fehler zurückgegeben - oder wurde gar nicht erst aufgerufen. Ohne korrelierten Trace mit Tool-Call-Ergebnissen, Modell-Inputs und Modell-Outputs ist das Rätselraten. Ich brauche eine Kette: Nutzereingabe, Routing-Entscheidung, Tool-Intent, Tool-Result, generierte Antwort. Lückenlos.
2. Kosten: Was kostet ein durchschnittlicher Supportfall - und welcher Agent-Pfad verbraucht die meisten Tokens?
Nicht jeder Supportfall ist gleich teuer. Ein einfacher FAQ-Lookup kostet ein paar hundert Tokens. Ein Refund-Flow mit Identitätsprüfung, Bestellabfrage und Approval-Schleife kann schnell das Zwanzigfache verbrauchen. Ohne Token-Attribution pro Agent, Tool und Conversation sehe ich nur eine monatliche Rechnung - aber nicht, wo das Geld hingeht.
3. Latenz: Wo hängt der Agent - am Modell-Call, am Tool-Call oder am Retrieval?
Der Nutzer wartet. Aber worauf? Auf das Modell, das 3 Sekunden für die Antwort braucht? Auf den lookup_order-Call, der gegen eine langsame Datenbank läuft? Oder auf ein Retrieval-System, das den Kontext zusammensucht? Span-basierte Latenz-Aufschlüsselung ist kein Nice-to-have - sie ist die einzige Möglichkeit, gezielt zu optimieren statt zu raten.
4. Qualität: Wie oft wählt der Agent das falsche Tool? Wie oft braucht er mehrere Versuche?
Der Agent hat vier Tools zur Auswahl. Wie oft greift er zum richtigen? Wie oft ruft er lookup_order auf, obwohl er verify_customer hätte aufrufen müssen - und korrigiert sich erst im zweiten Anlauf? Tool-Selection-Tracking und Retry-Counts zeigen mir, wo das Modell systematisch daneben liegt. Das sind keine Edge Cases - das sind Signale für Prompt-Probleme oder fehlende Tool-Descriptions.
5. Compliance: Kann ich den vollständigen Entscheidungspfad für einen konkreten Kundenvorgang nachvollziehen?
Kunde ruft an, will wissen, warum die Erstattung nicht angekommen ist. Regulierung verlangt Nachvollziehbarkeit. Ich brauche einen Audit-Trail, der zeigt: Welcher Agent hat wann welches Tool aufgerufen, welche Approval-Events gab es, wer hat was genehmigt? Ohne das ist jeder Kundenvorgang eine Black Box.
Fünf Fragen, fünf verschiedene Observability-Anforderungen. Und trotzdem passiert in der Praxis oft dasselbe: Es wird ein Tracing-Tool angebunden, ein paar Spans werden geschrieben - und dann hofft jeder, dass die richtigen Daten schon dabei sein werden.
In den meisten Teams fehlt nicht das Tooling - es fehlt die Klarheit darüber, welche Betriebsfragen beantwortet werden müssen.
Anatomie eines Traces
Fünf Fragen. Kein Dashboard, das sie beantwortet. Ändern wir das.
Nehmen wir den Refund-Agent und schauen uns an, was ein einzelner Support-Request als Trace erzeugt - wenn wir es richtig instrumentieren:
[ROOT] invoke_agent support-request
├── [LLM] chat gpt-5.4-nano (Routing-Entscheidung)
│ ├── gen_ai.usage.input_tokens: 674
│ ├── gen_ai.response.finish_reasons: ["tool-calls"]
│ └── gen_ai.response.model: gpt-5.4-nano
├── [TOOL] execute_tool lookup_order
├── [TOOL] execute_tool verify_customer
├── [EVENT] approval.requested (HITL-Pause)
│ └── wait_duration_ms, risk_level, tool_arguments
├── [EVENT] approval.granted (HITL-Resume)
│ └── approver_id, approval_id, justification
├── [TOOL] execute_tool refund_order (post-approval)
└── [LLM] chat gpt-5.4-nano (finale Antwort)
├── gen_ai.usage.input_tokens: 4083
├── gen_ai.response.finish_reasons: ["stop"]
└── gen_ai.response.model: gpt-5.4-nanoEin Trace, sieben Child-Spans. Jeder beantwortet eine andere Frage.
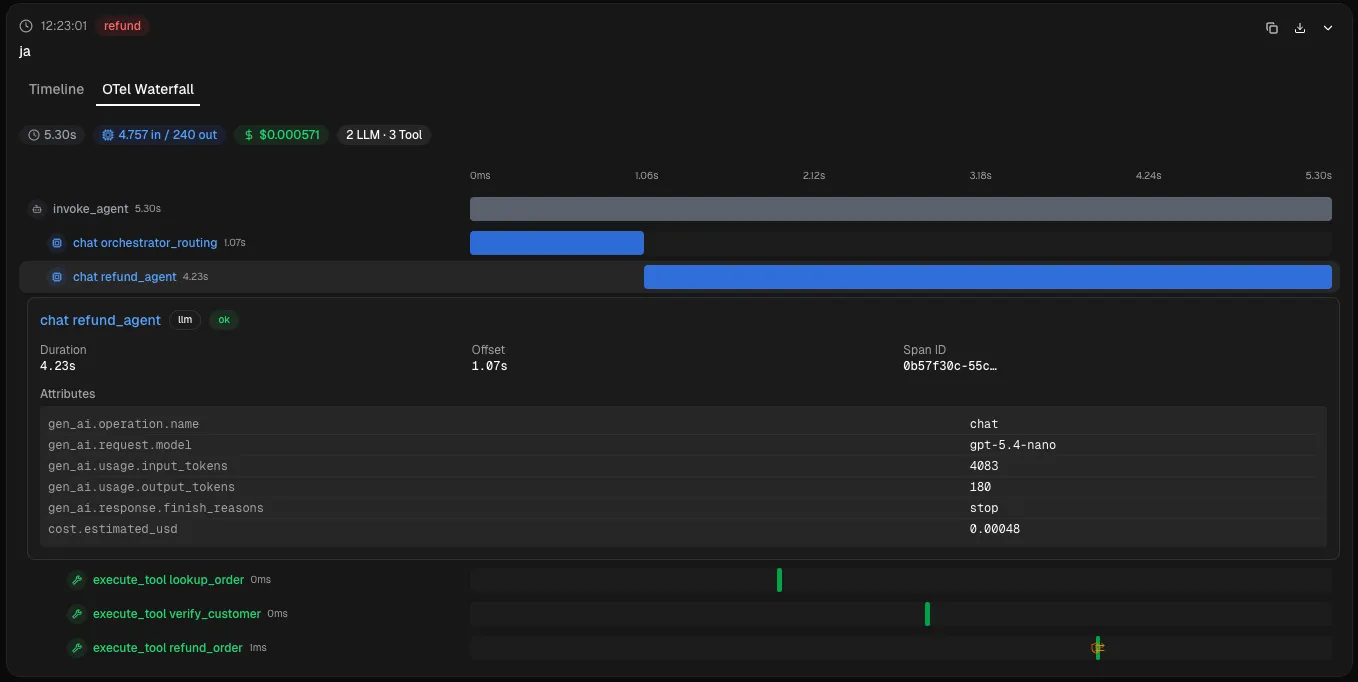
Schauen wir genauer hin.
Drei Span-Typen, drei Perspektiven
LLM-Calls (chat) sind die Modell-Interaktionen. Jeder Span trägt Token-Counts (gen_ai.usage.input_tokens, gen_ai.usage.output_tokens), das tatsächlich verwendete Modell (gen_ai.response.model - nicht immer identisch mit dem angeforderten) und die Finish-Reason. Drei LLM-Calls in einem Request? Das sind drei Kostenpunkte (Frage 2), drei Latenz-Beiträge (Frage 3), drei potenzielle Fehlerquellen.
Tool-Executions (execute_tool) erfassen jeden Werkzeug-Aufruf mit Argumenten und Ergebnis. verify_customer hat 40ms gedauert und valid: true zurückgegeben? Steht im Span. refund_order ist mit einem Timeout fehlgeschlagen? Steht auch im Span - und damit habe ich die Antwort auf Frage 1: Warum hat der Agent dem Kunden etwas bestätigt, das nie passiert ist?
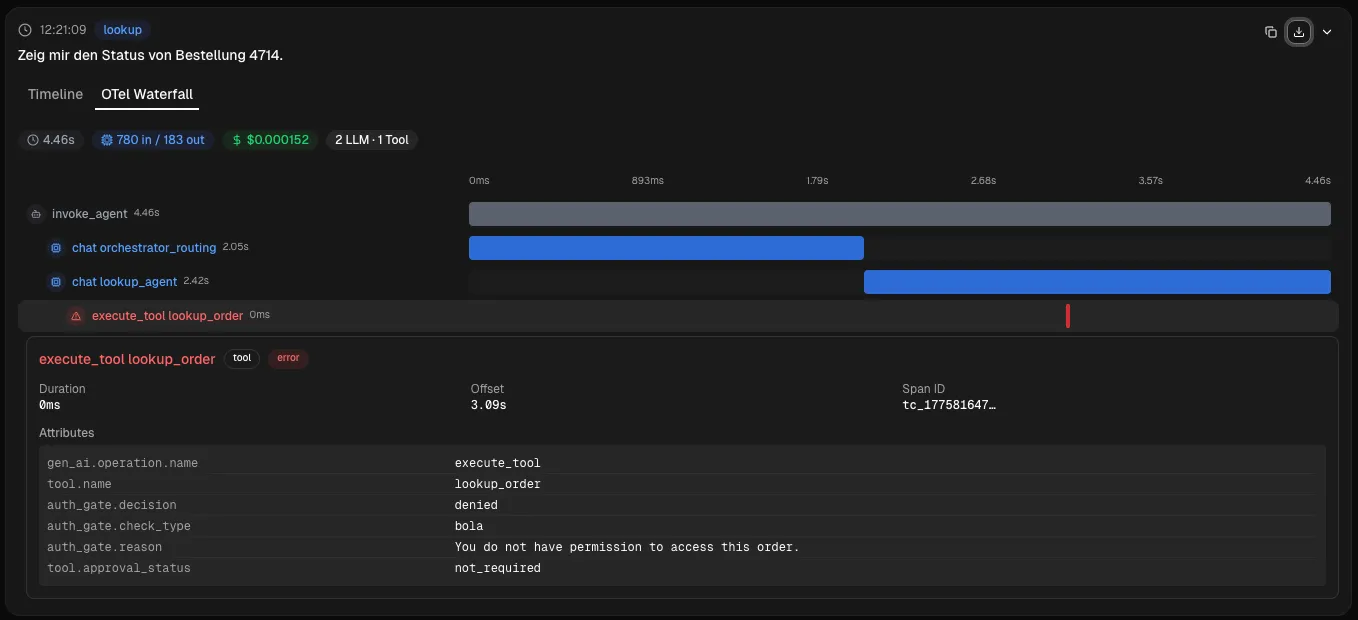
Agent-Orchestration (invoke_agent) ist der Root-Span - er hält alles zusammen. Gesamtdauer, Gesamtkosten, finaler Status. Wenn ich wissen will, ob der Refund-Agent langsamer wird, schaue ich hier. Wenn ich wissen will, warum, schaue ich in die Child-Spans.
Context Propagation: Wer hat was ausgelöst?
Ein Trace ohne Kontext ist ein Datenpunkt ohne Koordinatensystem - technisch korrekt, praktisch nutzlos. Die entscheidende Frage bei einem Incident ist nie “Was hat der Agent getan?”, sondern “Was hat der Agent für welchen Kunden in welchem Ticket getan?”
OpenTelemetry Baggage und Root-Span-Attributes lösen das: session.id, user.id, ticket.id wandern als Baggage durch den gesamten Trace. Jeder Span erbt den Kontext. Wenn der Refund-Agent um 14:32 einen falschen Betrag erstattet hat, finde ich über die ticket.id in Sekunden den vollständigen Trace - nicht durch Logfile-Archäologie.
Approval-Events im Trace
Im HITL-Post ging es um die Architektur von Approval-Gates. Hier geht es um deren Sichtbarkeit.

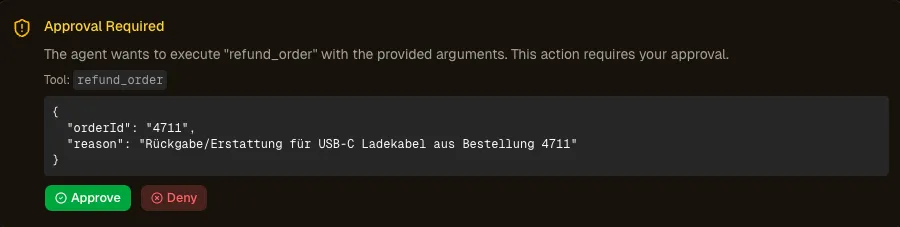
Stand April 2026 gibt es keine standardisierte OTel-Convention für Approval-Events. Das heißt: Custom Events. approval.requested und approval.granted als Span-Events auf dem Root-Span, mit Attributen wie wait_duration_ms, risk_level, approver_id und approval_id.
Warum das wichtig ist? Zwei Metriken fallen direkt heraus: Approval-Latenz (wie lange wartet der Workflow auf einen Menschen?) und Approval-Rate (wie oft wird genehmigt vs. abgelehnt?). Eine steigende Ablehnungsrate ist ein Signal. Entweder der Agent schlägt zunehmend fragwürdige Aktionen vor - oder die Approval-Kriterien sind zu streng. Beides will ich wissen.
Was NICHT in den Trace gehört
AI-Workloads erzeugen 10-50x mehr Telemetrie als klassische Services. Jeder LLM-Call hat einen Prompt, eine Completion, oft mehrere Tool-Calls mit Ergebnissen. Die Versuchung, alles zu loggen, ist groß.
Metadata und Referenzen sind der Default. Token-Counts, Modellversion, Finish-Reason, Tool-Name, Dauer - ja. Vollständiger Prompt-Text, API-Keys, rohes Kundenfeedback - nein. Nicht weil es technisch unmöglich wäre, sondern weil es im Normalfall unnötig ist.
Break-Glass-Architektur: Wenn du doch den vollen Content brauchst
Manchmal reichen Metadata nicht. Ein Halluzinations-Incident, ein eskalierter Kundenfall - da brauche ich den tatsächlichen Prompt und die Completion. Die Lösung ist keine Entweder-Oder-Entscheidung, sondern eine Zwei-Lanes-Architektur:
Production Lane: Minimierte Events, nur Metadata und Referenzen. Lange Retention, niedriges Risiko. Das ist der Normalzustand.
Break-Glass Lane: Voller Content, aktiviert durch einen Named-Approver mit dokumentierter Begründung. Kurze Retention (24-72h), automatische Löschung, vollständiger Audit-Trail. Jeder Zugriff ist nachvollziehbar.
Das Muster ist nicht neu - es ist dasselbe Prinzip wie bei Production-Database-Access oder Encryption-Key-Escrow. Der Unterschied: Bei AI-Workloads ist das Datenvolumen pro Request so hoch, dass die Default-Lane wirklich minimal sein muss, damit die Break-Glass-Lane überhaupt handhabbar bleibt.
Was OpenTelemetry liefert - und was nicht
Wer sich mit Observability für AI-Features beschäftigt, stößt auf die OpenTelemetry GenAI Semantic Conventions. Die Spec existiert, sie wächst, sie hat Momentum. Aber sie hat auch ein Problem: Stand April 2026 ist kein einziges Attribut Stable. Alles trägt den Status “Development”. Wer die Conventions heute nutzt, muss OTEL_SEMCONV_STABILITY_OPT_IN=gen_ai_latest_experimental setzen - und damit akzeptieren, dass sich Attribute jederzeit umbenennen können.
Das heißt nicht, dass die Spec nutzlos ist. Es heißt, dass wir wissen müssen, was sie kann - und vor allem, was sie nicht kann. (Kurze Begriffsklärung: Die Spec verwendet den Status “Development”, aber die Opt-In-Variable heißt experimental - ein historisches Überbleibsel. Gemeint ist dasselbe.)
Was die Spec abdeckt
Die Conventions definieren Span-Typen für die wichtigsten Operationen: chat, text_completion, embeddings, execute_tool, invoke_agent, invoke_workflow. Dazu kommen Kern-Attributes wie gen_ai.provider.name, gen_ai.request.model, Token-Counts und Finish-Reasons. Auf der Metrics-Seite gibt es gen_ai.client.token.usage als Histogram, gen_ai.client.operation.duration und Streaming-Metriken wie gen_ai.server.time_to_first_token.
Neuere Ergänzungen sind MCP-Conventions (mcp.method.name, mcp.session.id), Agent-Spans (invoke_agent, invoke_workflow) und ein gen_ai.evaluation.result-Event mit Score und Label. Die Richtung stimmt.
Was die Spec nicht abdeckt
Die Lücken betreffen genau die Dinge, die im Betrieb den Unterschied machen:
- Kosten-Tracking: Kein
gen_ai.cost-Attribut. Die Provider-APIs liefern Token-Counts, aber keine Preise. Plattformen wie Langfuse oder Helicone lösen das über gepflegte Preis-Tabellen - aber auf Spec-Ebene bleibt Kostenberechnung eine eigene Baustelle. - Prompt-Versioning: Kein Konzept von Prompt-Registries. Welche Version des Refund-Agent-System-Prompts zu welchem Ergebnis geführt hat - nicht abgedeckt.
- User Feedback: Kein standardisiertes Thumbs-Up/Down-Event. Die Verbindung zwischen Trace und Nutzerbewertung existiert in der Spec nicht.
- Approval und HITL: Keine Convention für Pause/Resume-Events. Wann ein Mensch eingegriffen hat und warum - unsichtbar.
- Guardrails: Kein Event für Content-Filtering oder Safety-Checks. Ob ein Output gefiltert wurde - nicht vorgesehen.
Die Spec liefert das Skelett: Modell, Provider, Tokens, Latenz. Alles, was AI-Features von der Spielerei zum Produktionssystem macht - Kosten, Versionen, Feedback, Governance - liegt außerhalb der Conventions.
Deprecated Attributes - was sich bereits geändert hat
Wer früh mit den Conventions gestartet ist, muss migrieren: gen_ai.system heißt jetzt gen_ai.provider.name, gen_ai.usage.prompt_tokens wurde zu gen_ai.usage.input_tokens, gen_ai.usage.completion_tokens zu gen_ai.usage.output_tokens. Ein Vorgeschmack darauf, was “Development”-Status in der Praxis bedeutet.
Die OTel GenAI Conventions sind ein guter Startpunkt - aber wer sich darauf verlässt, dass die Spec alle Observability-Anforderungen abdeckt, wird in Produktion überrascht.
Die sechs häufigsten Fehler bei LLM-Observability
Observability für AI-Features ist noch jung. Aber ein paar Fallen tauchen in Post-Mortems und Engineering-Blogs jetzt schon immer wieder auf. Sechs Anti-Patterns:
1. Alles loggen, nichts korrelieren
Application Logs existieren. Viele davon. Irgendwo steht, dass ein LLM-Call passiert ist. Irgendwo anders steht, dass ein Tool aufgerufen wurde. Aber zu welchem Kundenvorgang gehört das? Welcher Agent-Step hat den Call ausgelöst?
Ohne Trace-IDs als Klammer sind Logs nur Rauschen mit Zeitstempeln. Wenn der Refund-Agent eine Rückerstattung bestätigt, die nie ankam, will ich nicht in drei verschiedenen Log-Streams suchen - ich will einen Trace, der mir den gesamten Vorgang zeigt.
2. Prompts in Produktion vollständig loggen
Wie im Trace-Kapitel beschrieben: Content-Events gehören auf Opt-In, nicht Opt-Out. Trotzdem wird oft alles geloggt - aus Angst, im Incident etwas zu verpassen. Das Ergebnis: explodierende Speicherkosten und PII im Observability-Backend. Die bessere Frage ist nicht “Was könnten wir brauchen?”, sondern “Welche Metadata reichen für 95% der Fälle - und wie kommen wir an den Rest, wenn wir ihn brauchen?” Die oben skizzierte Break-Glass-Architektur löst genau das.
3. Token-Counts ohne Kostenzuordnung
“Wir verbrauchen 2 Millionen Tokens pro Tag.” - “Wofür?” - Schweigen.
Globale Token-Counts sind eine Zahl auf einem Dashboard. Nicht mehr. Ohne Metadata-Tagging an jedem API-Request - user_id, feature_name, agent_name - lässt sich nicht beantworten, welches Feature die Kosten treibt. Ist es der Refund-Agent? Die Zusammenfassung? Das Routing? Kostenoptimierung ohne Attribution ist Raten.
4. Nur den Happy Path instrumentieren
Das ist der gefährlichste Fehler. Tool-Fehler, Retries, abgebrochene Chains - alles unsichtbar. Die Error Rate sieht gut aus, weil nur erfolgreiche Abschlüsse gezählt werden.
Rechne nach: 10 Agent-Steps mit je 99% Accuracy landen bei 90% Gesamtaccuracy. Und jeder unsichtbare Retry multipliziert Kosten und Latenz, ohne dass es jemand merkt. Error-Spans, Retry-Counts und Finish-Reason-Tracking gehören an jeden Step - nicht nur an den letzten.
Was du nicht misst, optimierst du nicht. Was du nicht siehst, ignorierst du - bis es ein Incident wird.
5. Observability als Nachgedanke
“Wir machen erst die Features, dann die Observability.” Das klingt pragmatisch. In der Praxis heißt es: Im ersten Incident hast du keine Daten. Kein Trace, kein Span, keine Versionsinformation. Nur Vermutungen.
Observability ist eine Architekturentscheidung, keine Ops-Aufgabe für Sprint 12. Trace-Context, Span-Struktur und Metadata-Schema müssen stehen, bevor das erste Feature live geht. Nachträglich instrumentieren heißt nachträglich alle Abstraktionen aufbrechen.
Michael Seel macht in “AI Systems Architecture: Governance” den nächsten Schritt: Observability gehört nicht nur ins Team-Backlog, sondern in die Plattform - sonst entsteht Shadow AI analog zu Shadow IT.
6. Dashboard-Cargo-Cult
Latenz-Chart. Token-Count-Graph. Error-Rate-Gauge. Drei Dashboards, zwölf Panels, null Erkenntnisse. Niemand schaut drauf, bis ein Incident passiert - und dann helfen sie nicht, weil sie die falschen Fragen beantworten.
Ein Dashboard, das “Requests pro Minute” zeigt, beantwortet keine einzige Betriebsfrage. Wie hoch ist die Halluzinationsrate? Welcher Agent-Pfad kostet am meisten? Gibt es Prompt-Drift? Dashboards müssen Entscheidungen ermöglichen, nicht Metriken dekorieren.
Reifegradmodell: Von Blind bis Diagnostic
Es gibt kein offizielles “LLM Observability Maturity Model” - keinen ISO-Standard, kein Gartner-Quadranten-PDF. Aber wenn ich mir anschaue, wie Honeycomb, LangChain und Portkey das Thema beschreiben, zeichnet sich eine klare Progression ab. Ich habe sie in fünf Stufen verdichtet - nicht als akademisches Framework, sondern als Bewertungsraster für die eine Frage: Wo stehen wir, und was ist der nächste sinnvolle Schritt?
| Stufe | Name | Kennzeichen | Welche der fünf Fragen beantwortet werden |
|---|---|---|---|
| 0 | Blind | Keine Traces, nur Application Logs | Keine. Jeder Incident ist Spekulation. |
| 1 | Basic | Request/Response-Logging, Token-Counts | Frage 2 (Kosten) teilweise - aber ohne Antwort auf das Wo und Warum. |
| 2 | Structured | OTel-Traces mit GenAI-Conventions, Tool-Spans | Fragen 1 (Debugging), 3 (Latenz), 4 (Qualität). |
| 3 | Operational | Dashboards, Alerts auf Kosten/Latenz/Fehlerrate | Fragen 1-4 proaktiv. Kostencontrolling. SLOs. |
| 4 | Diagnostic | Trace-zu-Eval-Pipeline, Drift-Erkennung | Alle fünf Fragen - plus Feedback-Loop in die Evals. |
Die meisten Teams sind zwischen Stufe 0 und 1. Stufe 2 ist der sinnvolle nächste Schritt.
Das ist keine Vermutung. Wer heute console.log("LLM response:", result) in Produktion hat, ist auf Stufe 1. Wer nicht mal das hat - Stufe 0. Beides bedeutet: Wenn etwas schiefgeht, wird geraten statt diagnostiziert.
Stufe 2 - Structured Traces mit OpenTelemetry und den GenAI Semantic Conventions - ist der Punkt, ab dem Debugging aufhört, ein Ratespiel zu sein. Hier werden einzelne Requests nachvollziehbar: Welcher Prompt ging rein, welches Modell hat geantwortet, welche Tools wurden aufgerufen, wie lange hat jeder Schritt gedauert. Das ist mit überschaubarem Aufwand erreichbar - und zahlt sich ab dem ersten Incident aus.
Stufe 3 braucht mehr als Tooling - sie braucht organisatorische Reife. Dashboards bauen kann jeder. Aber sinnvolle Alerts definieren, SLOs für AI-Features formulieren, Kostenbudgets pro Feature durchsetzen - das sind Entscheidungen, die ein Team gemeinsam treffen muss.
Stufe 4 ist dort, wo Observability und Evals zusammenwachsen. Produktions-Traces fließen zurück in die Eval-Pipeline. Ein Incident wird nicht nur gefixt, sondern als Regressionstest verankert. Im Evals-Post habe ich geschrieben, dass Evals ohne Produktionsfeedback veralten - Stufe 4 schließt genau diese Lücke.

Wenn du nur eine Sache aus diesem Post mitnimmst: Starte mit den fünf Betriebsfragen aus dem ersten Kapitel, nicht mit dem Tooling. Die Stufe im Reifegradmodell ergibt sich daraus, welche dieser Fragen du heute beantworten kannst - und welche nicht.
Tooling-Entscheidung: Welches Setup passt?
“Welches Observability-Tool soll ich nehmen?” - Es kommt darauf an. Aber nicht auf Features - sondern auf die Frage, welche Schichten ich abdecken muss.
Das Zwei-Schichten-Modell
Observability für AI-Features zerfällt in zwei grundlegend verschiedene Fragestellungen:
Layer 1: Infrastruktur-Observability. Ist das System gesund? Wie hoch ist die Latenz? Wo brechen Requests ab? Das ist die Domäne von OpenTelemetry - Distributed Tracing, Metriken, Logs. Die GenAI Semantic Conventions erweitern OTel um LLM-spezifische Attribute wie gen_ai.usage.input_tokens oder gen_ai.request.model. Wer bereits ein OTel-Setup hat, bekommt damit die Infrastruktur-Sicht auf AI-Calls fast geschenkt.
Layer 2: Prompt-Level-Observability. Produziert die AI gute Outputs? Welche Prompt-Version performt besser? Wo halluziniert das Modell? Diese Fragen beantwortet OTel allein nicht - dafür brauche ich eine dedizierte LLM-Plattform mit Prompt-Playground, Eval-Pipelines und Session-Tracking.
Beide Schichten beantworten unterschiedliche Fragen. Beides in ein Tool zu pressen ist ein Kompromiss in beiden Richtungen.
Drei Szenarien
Ein Team mit OTel im Stack? Dann ergänzen die GenAI Semantic Conventions die Infrastruktur-Sicht, und Langfuse (oder eine vergleichbare Plattform) setzt für die Prompt-Level-Observability obendrauf auf.
Greenfield AI-Projekt? Für Startups: Langfuse Cloud, fertig. Schneller geht der Einstieg nicht. Für größere Organisationen: OTel von Tag 1 einplanen - das nachzurüsten wird mit jedem Service teurer. Plus eine LLM-Plattform für die zweite Schicht.
Compliance-Anforderungen? Dann zählt Self-Hosting. Langfuse ist vollständig self-hostbar und die klarste Option. LangSmith und Braintrust bieten Self-Hosting im Enterprise-Tier an, aber mit höherem Infrastruktur-Aufwand und eingeschränkter Kontrolle. Helicone ist Open Source und ebenfalls self-hostbar. Wer Daten nicht aus der Hand geben kann, hat Optionen - aber die Einstiegshürde variiert erheblich.
Oder: selber bauen?
Berechtigter Einwurf: Mit AI-Unterstützung lässt sich doch so ein Observability-Stack in ein paar Abenden zusammenstöpseln. Stimmt - für Layer 1. OTel-SDK, Grafana Tempo oder Jaeger als Backend, Grafana-Dashboards, ein paar eigene Span-Attribute für gen_ai.*. Kostentabelle als JSON, Prompt-Versionen als Hash im Span. Das ist keine Raketentechnik, und ich bin der Letzte, der davon abrät - im Gegenteil.

Layer 2 ist der härtere Teil. Prompt-Registry mit Diff-Ansicht zwischen Versionen, Eval-Pipelines mit LLM-as-Judge, Session-Threading über lange Konversationen, Feedback-Capture mit UI für Product und QA. Das sind nicht “ein paar Abende” - das ist eine eigene Plattform.
Die pragmatische Variante: Layer 1 selbst bauen, bei Layer 2 eine Plattform andocken. Langfuse lässt sich per OTel-Bridge an einen selbstgebauten Layer-1-Stack anschließen - Best of both.
Kurzeinschätzungen: Langfuse, Arize Phoenix, LangSmith, Helicone, Braintrust
Langfuse - Das stärkste Open-Source-Gesamtpaket. Self-hostbar, OTel-Bridge für die Infrastruktur-Anbindung, Prompt-Management, Eval-Pipelines. Die Community wächst schnell und die Plattform deckt beide Schichten zunehmend ab. Für die meisten Teams der sicherste Einstieg.
Arize Phoenix - Best-in-class für RAG-Debugging und Embedding-Analyse. Local-first, ideal für die Entwicklungsphase. Wer viel mit Retrieval arbeitet und Chunk-Relevanz verstehen will, findet hier die besten Werkzeuge.
LangSmith - Der natürliche Fit für Teams, die bereits im LangChain-Ökosystem arbeiten. Tiefe Integration, gute Developer Experience. Self-Hosting ist als Enterprise-Add-on verfügbar, erfordert aber signifikante Infrastruktur (16+ vCPU, 64+ GB RAM). Wer nicht an LangChain gebunden ist, hat wenig Grund, hier zu starten.
Helicone - Open Source (MIT-Lizenz) und self-hostbar. In der Cloud-Variante der schnellste Einstieg überhaupt: Proxy-URL tauschen, fertig. Gut für erste Einblicke in Kosten und Latenz. Self-Hosted umgeht das Compliance-Problem des Proxy-Ansatzes.
Braintrust - Das stärkste Eval-Framework im Vergleich. Wer systematische Evaluations als Kernprozess etablieren will, findet hier die ausgereiftesten Werkzeuge. Self-Hosting im Enterprise-Tier als Hybrid-Modell: Data Plane im eigenen Account, Control Plane bei Braintrust.
Wie alles zusammenläuft
Dieser Post ist kein Einzelstück. Er ist die logische Konsequenz aus allem, was in den letzten Wochen geschrieben wurde - und er operationalisiert die Konzepte der vorigen Posts:
- Contracts als Grundlage - Schema-Validierung gegen den Modelloutput. In der Observability-Welt wird diese Validierung zum Span-Attribut: Hat das Schema gepasst? Wann, wo und wie oft hat es nicht gepasst?
- Evals leben nicht nur in der CI. Produktions-Traces werden zu Eval-Datensätzen - der offene Thread “Evals ohne Produktionsfeedback veralten” löst sich hier ein.
- Tool-Sicherheit wird durch Tool-Spans greifbar. Ein False Success - das Tool meldet Erfolg, aber nichts ist passiert - wird erst sichtbar, wenn der Tool-Span die tatsächliche Backend-Response als Event trägt.
- Human-in-the-Loop hinterlässt Approval-Events im Trace. Und die Rubber-Stamp-Detection, die ich dort als Design-Pattern beschrieben habe? Sie wird zur Metrik: durchschnittliche Review-Dauer, Reject-Rate, Approval ohne Kontextänderung.
Und wer glaubt, Observability sei optional
Der EU AI Act macht es zur Pflicht.
Art. 12 verlangt “automatic recording of events” für High-Risk-Systeme - und meint damit nicht console.log. Art. 12 verlangt, dass ein Deployer versteht, was das System getan hat. Art. 14 fordert Human Oversight mit der Fähigkeit, “die Fähigkeiten und Grenzen des Systems richtig zu interpretieren” - ohne Traces ist das eine leere Forderung. Art. 19 schreibt eine Aufbewahrungsfrist von mindestens sechs Monaten vor. Und Art. 72 verlangt Post-Market Monitoring - also genau die systematische Analyse von Produktionsdaten, die dieser Post beschreibt.
EU AI Act - die relevanten Artikel
- Art. 12 - Record-keeping: High-Risk-Systeme müssen automatische Aufzeichnung von Ereignissen (Logs) führen, die Traceability über die gesamte Lebensdauer sicherstellen.
- Art. 14 - Human Oversight: Aufsichtspersonen müssen die Fähigkeiten und Grenzen des Systems interpretieren können. Setzt Zugang zu Traces und Metriken voraus.
- Art. 19 - Aufbewahrungspflicht: Logs müssen mindestens 6 Monate gespeichert werden.
- Art. 72 - Post-Market Monitoring: Anbieter müssen Produktionsdaten systematisch sammeln und analysieren.
Die Deadline für High-Risk-Pflichten ist August 2026. Diese Artikel bilden eine regulatorische Kette, die exakt die Observability-Infrastruktur verlangt, die in diesem Post beschrieben wird. Wer sie ohnehin baut, hat die technische Grundlage für Compliance. Wer sie nicht baut, hat bald ein Problem.
Ausblick: Von Traces zu Regressionstests
Der nächste logische Schritt ist die Trace-zu-Eval-Pipeline. Ein produktiver Incident - ein halluzinierter Betrag, ein False Success, ein übersehener Edge Case - wird zum Trace. Der Trace wird zum Eval-Datensatz. Der Eval-Datensatz wird zum dauerhaften Regressionstest in der CI. Kein Incident darf zweimal auf die gleiche Weise passieren.
Observability ist kein Ops-Thema. Ohne sie bleiben Contracts, Evals und Human Oversight Konzepte, die ich nicht sehe, wenn sie brechen.