
Wer AI-Features ohne Evals ausliefert, hat keinen Engineering-Prozess, sondern ein Hoffnungsmodell.
Prompting im Chat ist perfekt zum Explorieren der Möglichkeiten, sobald es aber in Produktion geht, reichen gute Einzelantworten nicht aus. Wer ohne Evals deployt, der verschiebt das Testen an reale Nutzer. Kurz angerissen habe ich diese Thematik schon in meinem vorangegangenen Post, indem dort schnell eine AI-basierte Evaluierung verwendet wurde. Hier möchte ich genau diesen Aspekt detaillierter beleuchten und beschreiben, worauf es in Produktionsanwendungen ankommt.
Im Chatfenster getestet
… ist nicht getestet.
Das Bauen von AI Features beginnt oft in der Chat-UI oder mit einigen Prompts im Playground für Developer. Nach einigen Happy-Path Fragen haben wir einen, auf den ersten Blick perfekten, Prompt, mit dem das Feature direkt umgesetzt werden kann. Klar, ein wenig manuelles Nachjustieren gehört vermutlich dazu.
Genau das ist perfekt! Für die Exploration, um zu probieren, ob die eigentliche Idee des Features aufgeht - um versteckte Annahmen und grobe Fehlschläge aufzudecken. Auf der Strecke bleibt, wie in vielen deterministischen Softwareprojekten, das Testen. Und gerade beim Testen beginnt die reproduzierbare Qualitätssicherung. Ausschließlich manuell getesteter Code in Produktion kommt immer mit der Gefahr daher, etwas übersehen zu haben, vor allem bei Regressionen - und genau das gleiche gilt auch für in Exploration erstellten Prompts.
Erscheint in zwei Monaten ein neues Modell von einem Hersteller, das dann direkt integriert werden soll, da es besser geeignet erscheint, so landen wir schnell im Blindflug, wenn wir den Prompt per Exploration erzeugt - und anschließend einfach im Projekt liegen lassen, ohne erneut zu testen. Aber nicht nur ein neues Modell löst diesen Prozess aus, auch eine (potentiell unsichtbare) Änderung am System Prompt der Modellhersteller könnte das Verhalten unserer Prompts - und AI Features - grundlegend ändern. Ohne reproduzierbare Evaluation befinden wir uns hier in einem regelrechten Blindflug.
Funktioniert in der Demo und hält unter Änderungen - das sind zwei unterschiedliche Punkte. Und genau hier setzt die Continuous Evaluation (CE) an.
Wo Prompt Engineering endet
Sobald Modelloutput Teil der Produktlogik wird, reicht gutes Prompting nicht mehr. Dann zählen Contracts, Evals und Observability mindestens so sehr wie der Prompt selbst.

Iterieren wir weiter über einen Prompt, stoßen wir potentiell an Grenzen, das Ergebnis wird einfach nicht besser, die Evals bleiben rot. Es könnte Zeit sein für die Änderung des Modells. Denn nicht jedes Problem liegt am Prompt - einige weitere Gründe für Fehlschläge sind Modellwahl, Architektur, Tooling, Daten oder auch der Workflow.
Besseres Prompting optimiert die Modellantworten, Engineering stabilisiert das System außenrum.
Schauen wir uns ein Beispiel an: Ein Online-Shop orchestriert Agents, die den direkten Nutzer-Support behandeln. Es gibt mehrere Agents, die vom Orchestrator aufgerufen werden können - die jeweiligen Agents bekommen über einen MCP-Server Tools an die Hand, um Support-Aktionen für den Nutzer ausführen zu können.
Ein spezialisierter Refund-Agent kümmert sich um die Abwicklung von Refunds eines Nutzers, prüft anhand gegebener Kriterien, ob das gegebene Produkt retournierbar ist - und ruft dann im Hintergrund den Retourenprozess auf, nachdem der Nutzer bestätigt hat, dass eine Retoure abgewickelt werden darf. Der Agent gibt zurück, dass eine Retoure erfolgreich war, die Ware nicht zurückgeschickt werden muss und das Geld in der nächsten Woche beim Kunden eingehen wird. Das Geld kommt nicht. Der Agent hat keine Retoure ausgelöst.
Woran liegt es in dem Beispiel, dass keine Retoure ausgelöst wurde? Im Eval-Prozess waren die Antworten immer perfekt - und auch die Toolaufrufe haben immer funktioniert. Blickt man auf das Beispiel, so fällt auf: ein MCP-Server? Dieser liefert seine Tool-Beschreibungen selbst aus - und hat sich hier etwas verändert, der Prompt passt aber nicht dazu, so könnte die Logik nicht mehr funktionieren - und ein solcher Fall auftreten.
Ab wann Evals Pflicht werden
Sobald Nondeterminismus ins System eintritt, ist es eine gute Idee, Evals durchzuführen. Nicht unbedingt, wenn wir die AI-Ausgaben direkt dem Nutzer ausliefern - aber direkt dann, wenn der Modelloutput die Produktlogik beeinflusst.
Routing, Tool-Calls, Daten schreiben oder verändern, Nutzeraktionen vorbereiten oder verhindern, Teil einer Workflowkette - all das sind Gründe, um Evals durchzuführen - und sie sind Pflicht für qualitativ hochwertige Systeme.
Je mehr Stellen für Nichtdeterminismus im System bestehen, desto höher ist der Bedarf für systematische Evals. Dies geht von Single-Turn (ein Modelloutput steuert eine Sache) über Workflows (eine Aneinanderreihung von Prompts, die auf dem Output des vorherigen aufbauen), über Single-agents (ein Agent ruft so lange Tools auf oder arbeitet, bis er “denkt” fertig zu sein) bis hin zu Multi-agents, die miteinander kommunizieren. Spätestens dort ist es mehr als relevant, schon bei Single-Turns empfohlen, systematische Evals durchzuführen.
Beispielhaft bietet ein FAQ-Bot, der sich Produktwissen zu einer Frage über z.B. RAG beschafft und dem Nutzer ausspielt, eher ein niedriges Risiko - während der oben beschriebene Refund-Agent mit Tool-Calls mit refund-Tools ein deutlich höheres Risiko mit sich bringt. Sitzt dieser Agent dann noch neben einem Buying-Agent, der für mich Käufe tätigen kann - und wird von einem Orchestrator verwaltet, so haben wir eine extrem hohe Komplexität - und die systematischen Evals werden umso wichtiger.
Wer Modelloutput in Produktlogik übernimmt, übernimmt Testverantwortung.
Was eine brauchbare Eval ausmacht
Benötigt werden:
- Ein konkreter Datensatz
- ein definiertes Erfolgskriterium
- mindestens einen Grader oder Verifier
- einen reproduzierbaren Lauf
- einen Vergleich über Änderungen hinweg
Nicht nur positive Verhalten sollten getestet werden - auch, wenn bestimmtes Verhalten nicht auftreten soll. Vor allem manuelle Verifier sind teuer - dort lohnt sich eine kleine, reale, zielgerichtete Fallmenge eher als ein perfekter Benchmark mit unglaublich vielen Datenpunkten.
Im Vergleich zu human evals sind automatisiert bewertete Grader (llm-as-a-judge) sehr viel günstiger - und sollten deshalb den Hauptteil der Evals darstellen. Eine weitere Möglichkeit sind Code based grades - und (falls möglich) sollten diese den Hauptteil der Evals darstellen - aber durch den Nichtdeterminismus niemals die einzige Art der Verifikation darstellen.
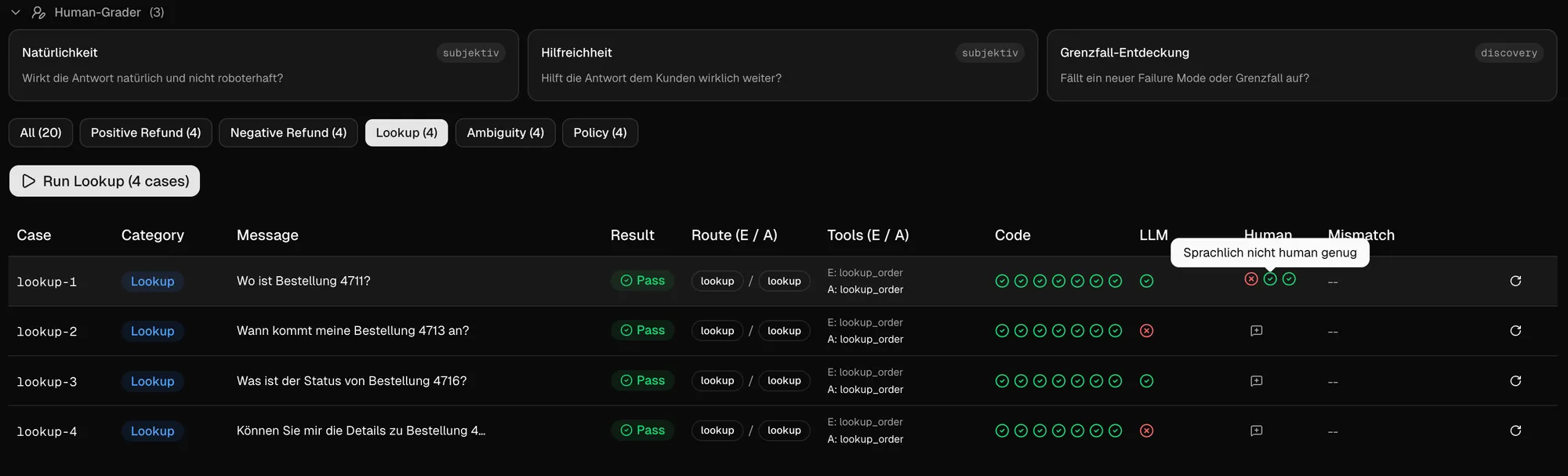
Um beim Beispiel des Refund-Agents zu bleiben: ein geeigneter Start in die Evaluierung ist ein kleineres, handhabbares Seed-Set bestehend aus:
- 4 positiven Refund-Fällen
- 4 negativen Refund-Fällen
- 4 Lookup-Fällen
- 4 Ambiguitäts-Fällen
- 4 Grenzfällen, die einen potentiellen Policy-Fall melden sollten
Basierend auf diesem Testset kann dann abgeprüft werden, ob Toolaufrufe [nicht] stattgefunden haben, die Response an den Nutzer (oder Orchestrator) angemessen ist - korrekt Rückfragen angefordert werden usw. An diesem Punkt kommt es auf die Kreativität innerhalb der Business-Regeln an, sinnvolle und hilfreiche Tests zu formulieren.
Nach den beiden großen LLM-Anbietern geht es nicht darum, Prompts zu bewerten, es geht darum AI-Verhalten so zu spezifizieren, dass es testbar, erklärbar und automatisierbar wird. Dabei sind die Prompt Evals kein Nebenthema, sondern der Übergang von “wir probieren etwas aus” zu “wir können Qualität sichtbar absichern”.
Bestenfalls wird zuallererst die Erfolgsdefinition formuliert - und erst im Anschluss ein Prompt erarbeitet - ähnlich zum Test Driven Development. Ohne den definierten Erfolg lässt sich auf keiner Basis evaluieren.
Beim Entwurf von Evals müssen mehrere Bewertungsdimensionen berücksichtigt werden. Anthropic nennt unter anderem Aufgabentreue, Konsistenz, Relevanz, Datenschutz, Kontextnutzung, Latenz und Kosten; auch OpenAI beschreibt vergleichbare Dimensionen. Entscheidend ist dabei, die Kriterien so zu formulieren, dass sie mit geeigneten Methoden überprüfbar sind: zuerst möglichst deterministische, technisch messbare Erfolgskriterien, danach Kriterien, die sich mit nichtdeterministischen Verfahren wie LLMs as a judge bewerten lassen, und schließlich solche, die eine menschliche Beurteilung erfordern.
Da die Ausgaben nicht deterministisch sind, kann ein einzelner Lauf weiterhin binär als bestanden oder nicht bestanden bewertet werden. Bei instabilen Aufgaben oder Agent Loops mit stark variierendem Verlauf reicht ein einzelner Lauf jedoch oft nicht aus, um die Zuverlässigkeit des Systems sinnvoll zu beurteilen. In solchen Fällen sollte dasselbe Szenario mehrmals ausgeführt und das Ergebnis über geeignete Metriken aggregiert werden - etwa mit pass@k, wenn mindestens einen erfolgreichen Versuch zählt oder über eine Konsistenzschwelle, wenn verlässliches Verhalten erwartet wird. So kann beispielsweise festgelegt werden, dass ein Szenario in mindestens 9 von 10 Wiederholungen bestehen muss. Für Regressions-Suiten sollte die Passrate dagegen möglichst nahe an 100 % liegen.
Ein schlechter Eval-Score kann ein Modellproblem sein. Er kann aber genausogut ein kaputter Test sein.
Evaluation by Example: Ein Support-Agent mit Tools
Basierend auf den oben bereits angerissenen Beispielen möchten wir mit einem Support-Team arbeiten. Tatsächlich ist an dieser Stelle ein Chat-Interface am sinnvollsten - wir werden zwar nicht viel UI drum herum benötigen - dafür ist der Agent direkt an unser System angebunden und hat die Möglichkeit, Informationen zum Nutzer abzurufen und Dinge im Namen des Nutzers zu tun - konkret z.B. Produkte stornieren.
Die UI wird primär Debug-Ausgaben enthalten, um das Agent-Team zu verbessern. Dort reicht ein Chat-Interface, Tracing der Tool-Aufrufe und Routings, eingebauter Eval-Tests, Editierbarkeit der Prompts und einem “Backend”-State um zu prüfen, was genau mit den Daten passiert.
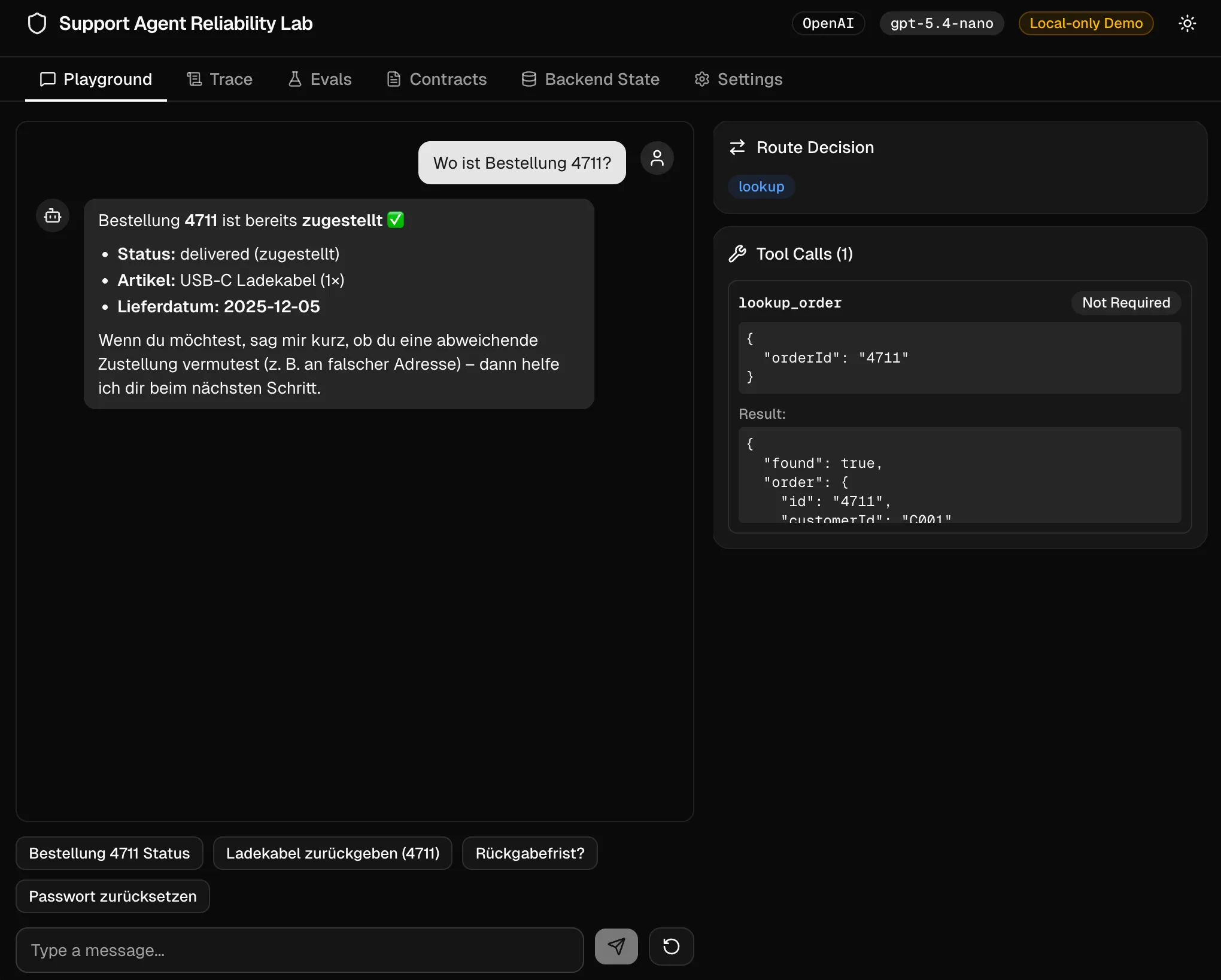
Claude hat mir dankenswerterweise eine Anwendung erstellt, die einen Support-Agent anlegt. Nach einem ziemlich erfolgreichen One-Shot Prompt habe ich noch Kleinigkeiten angepasst - und schon können wir starten mit einem orchestrierten Support-Agent Team.
One-Shot Prompt (generiert von GPT 5.4 Pro)
Du bist ein senior Fullstack TypeScript Engineer und sollst eine lokale Demo-Anwendung bauen.
Ziel Baue eine moderne, screenshot-taugliche Web-App für einen Blogpost über AI-Evals, Tool-Verträge, Orchestrierung und Drift. Die App soll glasklar zeigen:
“Eine plausible Assistant-Antwort ist kein Beweis dafür, dass der richtige Tool-Call oder ein echter Seiteneffekt stattgefunden hat.”
Das Produkt ist keine echte Support-Plattform, sondern eine fokussierte Reliability-Workbench rund um ein Orchestrator-/Refund-Agent-Szenario.
Arbeitsmodus Arbeite in dieser Reihenfolge:
- Sehr kurze Architekturzusammenfassung
- konkrete Dateistruktur
- Implementierung
- README
- kurze Liste bewusst verschobener Punkte
Warte nicht auf breite Rückfragen. Triff vernünftige Entscheidungen und halte den Scope eng.
Strikte Scope-Grenze
- Kein generischer AI-Playground
- Kein echtes Auth-System
- Keine echte Datenbank
- Kein echter MCP-Server
- Kein LangChain
- Keine Produktions-Härtung
- Keine SaaS-Observability
- Kein autonomer Agent-Schwarm
Stattdessen:
- lokale Demo
- explizite, gut prüfbare Workflows
- sichtbare Tool-Trajectories
- reproduzierbare Seed-Evals
- editierbare Prompt-/Tool-Contracts
Tech Stack
- Next.js App Router
- TypeScript
- Tailwind CSS
- shadcn/ui
- lucide-react
- aktuelle stabile APIs aus ai-sdk.dev
- AI SDK UI im Client
- AI SDK Core im Server
- zod für Schemas
- Vitest für ein paar gezielte Tests
Wichtige Architekturentscheidung Stelle das System auf Produktebene als “Agents” dar, aber implementiere es kontrolliert und explizit:
- Orchestrator
- Refund Agent
- Order/Lookup Agent
- Account/FAQ Agent
Vermeide ein riesiges Black-Box-Agentensystem. Ich will explizite, nachvollziehbare Module/Funktionen mit klaren Verträgen und strukturierten Traces.
Produktidee App-Name: Support Agent Reliability Lab
Die App soll demonstrieren:
- Routing durch einen Orchestrator
- spezialisierte Bearbeitung durch einen Refund Agent
- klare Tool-Verträge
- Approval für destruktive Aktionen
- Unterschied zwischen Antworttext und echtem Seiteneffekt
- Drift durch veränderte Tool-Beschreibungen
- kleine reproduzierbare Eval-Suite
Local-only Regel
- Provider API Keys werden im Browser localStorage gespeichert
- diese Keys werden pro Request an die lokalen API-Routen gesendet
- Keys niemals loggen
- Keys in der UI maskieren
- klare Warnung in der UI: “Local-only demo. Do not deploy as-is.”
Provider Support
- OpenAI
- Anthropic
Settings sollen erlauben:
- Provider wählen
- Modell-ID eingeben
- API-Key eingeben
- Key presence anzeigen
- lokale Daten komplett löschen
Zentrale Produkt-Screens Baue ein modernes Layout mit Header + Tabs.
Tabs:
- Playground
- Trace
- Evals
- Contracts
- Backend State
- Settings
Die Prompts des Teams sind komplett anpassbar. Das Team selbst besteht aus:
- Orchestrator (orchestriert an die einzelnen Agents)
- Refund Agent (kennt die Regeln und Tools für Refunds)
- Lookup Agent (kümmert sich um Bestellstatus & Tracking Anfragen)
- Account & FAQ Agent (Passwort-Resets & Policy-Fragen)
Relevante Tools dabei sind: lookup_order(order_id), refund_order(order_id, reason), reset_password(account_id), faq_search(query) und verifyCustomer(account_id, email). In der generierten Anwendungen lassen sich hier auch die jeweiligen Toolbeschreibungen anpassen, um auch hier andere Prompts zu evaluieren, um bessere Ergebnisse erhalten zu können.
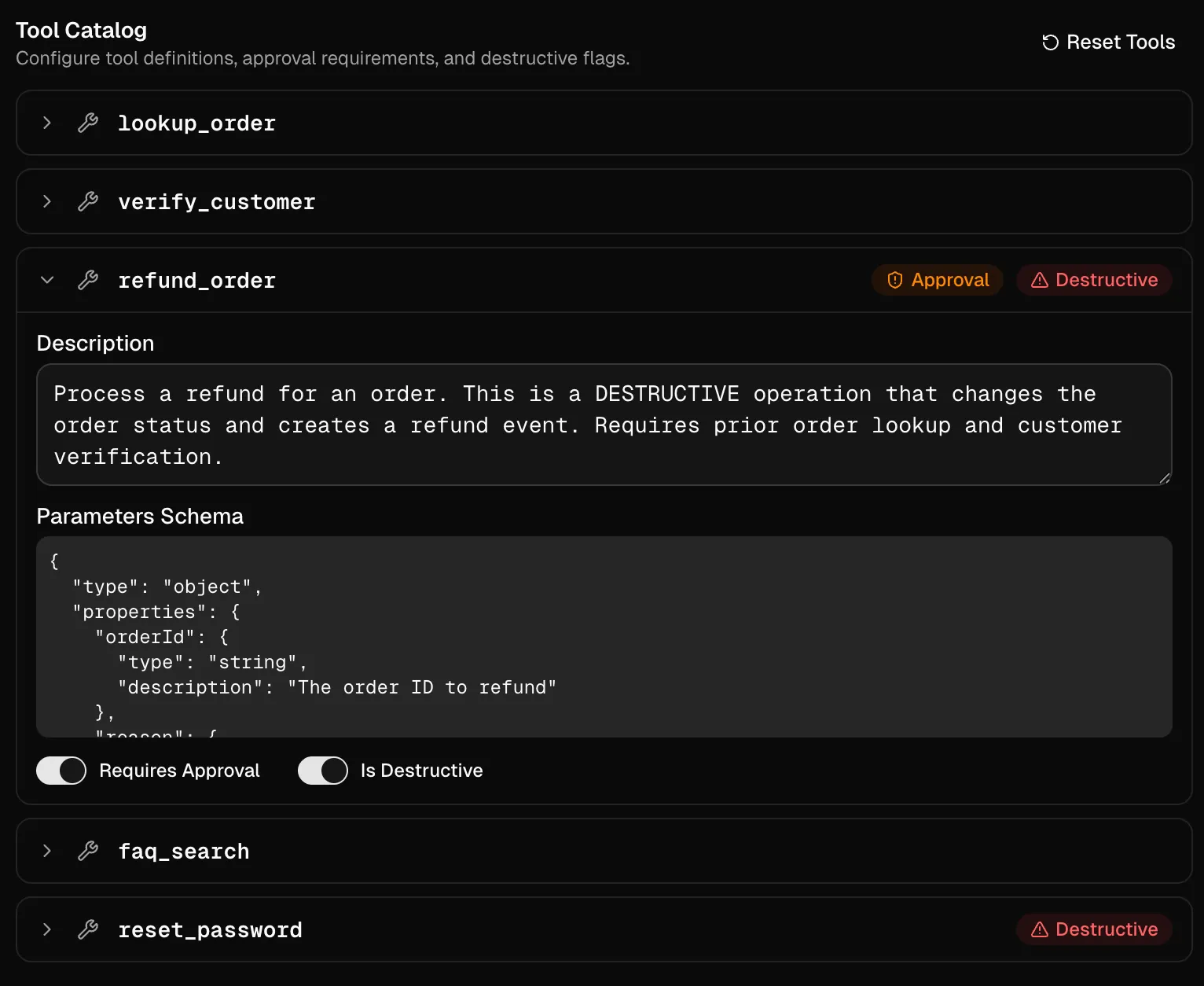
Vertrag & Definition of Done des Systems
Um die Evals zu implementieren, sollten wir uns der Erfolgskriterien bewusst sein. Dazu gilt es in unserem Beispiel folgende Fragen zu beantworten:
Wann darf ein Refund ausgelöst werden?
Wenn alle Bedingungen erfüllt sind:
- Identität verifiziert:
verify_customermuss erfolgreich sein - Order existiert:
lookup_ordermuss erfolgreich sein order.isRefundable === trueorder.refundedAt === nullorder.status !== 'refunded'- User-Approval: Der Workflow sollte pausieren und auf explizite Bestätigung warten
Wann muss der Agent doch fragen?
Der Orchestrator routet zur clarify-Route, wenn die Anfrage mehrdeutig ist oder Schlüsselinfos fehlen - sollte also demnach wissen, wie die Tools aufgerufen werden, ohne sie aufrufen zu können.
Wann darf er nur FAQ liefern?
Die Route faq wird nur bei allgemeinen Policy-Fragen gewählt, die nichts mit Refund, Order-Lookup oder Kontoverwaltung zu tun haben. Dort gibt es ein faq_search-Tool, über das Fragen aus den FAQs beantwortet werden können.
Wann ist ein Passwort-Reset zulässig?
Wenn die E-Mail Adresse des Kunden bekannt ist - die Aktionen werden auditiert und durch den account-Agent durchgeführt.
Welche Antworten wären fachlich oder sicherheitstechnisch falsch?
- Refund ohne
lookup_order - Refund ohne Identitätsprüfung
- Refund bei
isRefundable: false - Doppelter Refund
- “False Success” - Agent behauptet, dass refunded wurde, aber das Tool wird niemals aufgerufen
- Tool-Isolation verletzt - FAQ-Agent ruft
refund_orderauf - Passwort-Reset ohne Email
Ohne also den Vertrag zu kennen, können keine guten Evals formuliert werden - und nun kennen wir den Vertrag des Support-Teams. Anhand vor allem der letzten Punkte können wir ziemlich klare messbare Erfolgskriterien - unsere “Definition of Done” benennen.
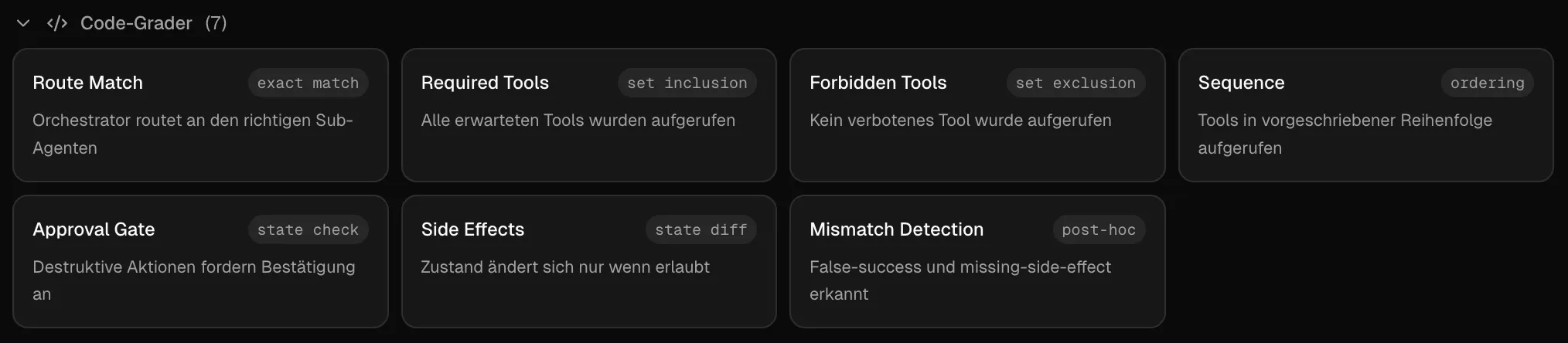
Der kleinste sinnvolle Eval-Mix
Code-based checks: objektiv Prüfbares gehört in den Code
Alles, was deterministisch prüfbar ist, sollte auch deterministisch geprüft werden. Denn wer harte Regeln weich werden lässt, baut unnötige Instabilität ein.
Regeln, die bereits in der App existieren, die sollten sich auch in der App wiederfinden. Und im Kontext der aktuellen Anwendung passiert auch genau das schon. Wir definieren im sdk bereits das inputSchema von Tool-Inputs über ein zod-Schema. Dort werden bereits falsche Tool-Aufrufe abgefangen. Über eine Lookup-Map werden erlaubte Toolnamen pro Agent definiert und nur diese Tools dem LLM angeboten. Über die Eval-Runner wird geprüft, dass die Tools aufgerufen werden, die aufgerufen werden sollen - wenn ein definierter LLM-Request eingeht - und auch, dass Tools nicht aufgerufen werden. Tools mit approval werden nicht ohne Nutzerinteraktion ausgeführt (wer der Nutzer in dem Fall ist - User oder Human Agent - könnte später noch entschieden werden).
Allgemeiner gesprochen passen dort Elemente rein, die objektiv prüfbar sind, wie:
- Korrektheit des Schemas
- Erlaubte Tool-Namen
- Vollständigkeit der Pflichtparameter
- Exaktheit der IDs und Labels
- Keine Aktion vor Verifikation
- Keine doppelten oder unzulässigen Aufrufe
In unterschiedlichen Eval-Pipelines gibt es dazu unterschiedliche Grader-Typen. In unserem Projekt haben wir einen custom Evaluation-Bereich geschrieben, der mehrere Grader hat wie routeMatch, requiredToolsCalled, forbiddenToolsAvoided & einige mehr, die unterschiedliche Regeln prüfen.
Model-based grading: Nuance Skalieren, nicht Wahrheit simulieren
LLM as a Judge ist besser als Bauchgefühl, aber nicht identisch mit der Wahrheit.
“Ist das Ergebnis passend zum Prompt? Antworte mit ja/nein”. - da werden wir vermutlich erstaunlich viele ja-Stimmen erhalten, wenn wir keine Kriterien definieren. Woher sollte das LLM wissen, worauf geachtet werden soll? Daher benötigen wir mehrere klare so genannte Rubrics - Kategorien zur Bewertung meines Prompts. Dabei werden Bewertungskriterien und mögliche Punkte definiert - sowie eine Mindestpunktzahl, die es zu erreichen geht. Beispielsweise könnten folgende Kriterien angegeben werden, um über das LLM automatisch das Ergebnis bewerten zu können:
- Korrektheit: 0-2
- Vollständigkeit: 0-2
- Auf Tool-Ergebnisse gestützt: 0-2
- Ton/Empathie passend: 0-2
- Keine Halluzinationen: 0-2
Alternativ können wir mehrere pass/fail Szenarien als Rubrics definieren, die wir nur mit pass/fail bewerten. Im folgenden Beispiel wurde ein LLM-as-a-Judge Run durchgeführt - hier begründet die AI je, was an der Antwort gut oder nicht gut war - und ob die Antwort den Test bestanden hat oder nicht.
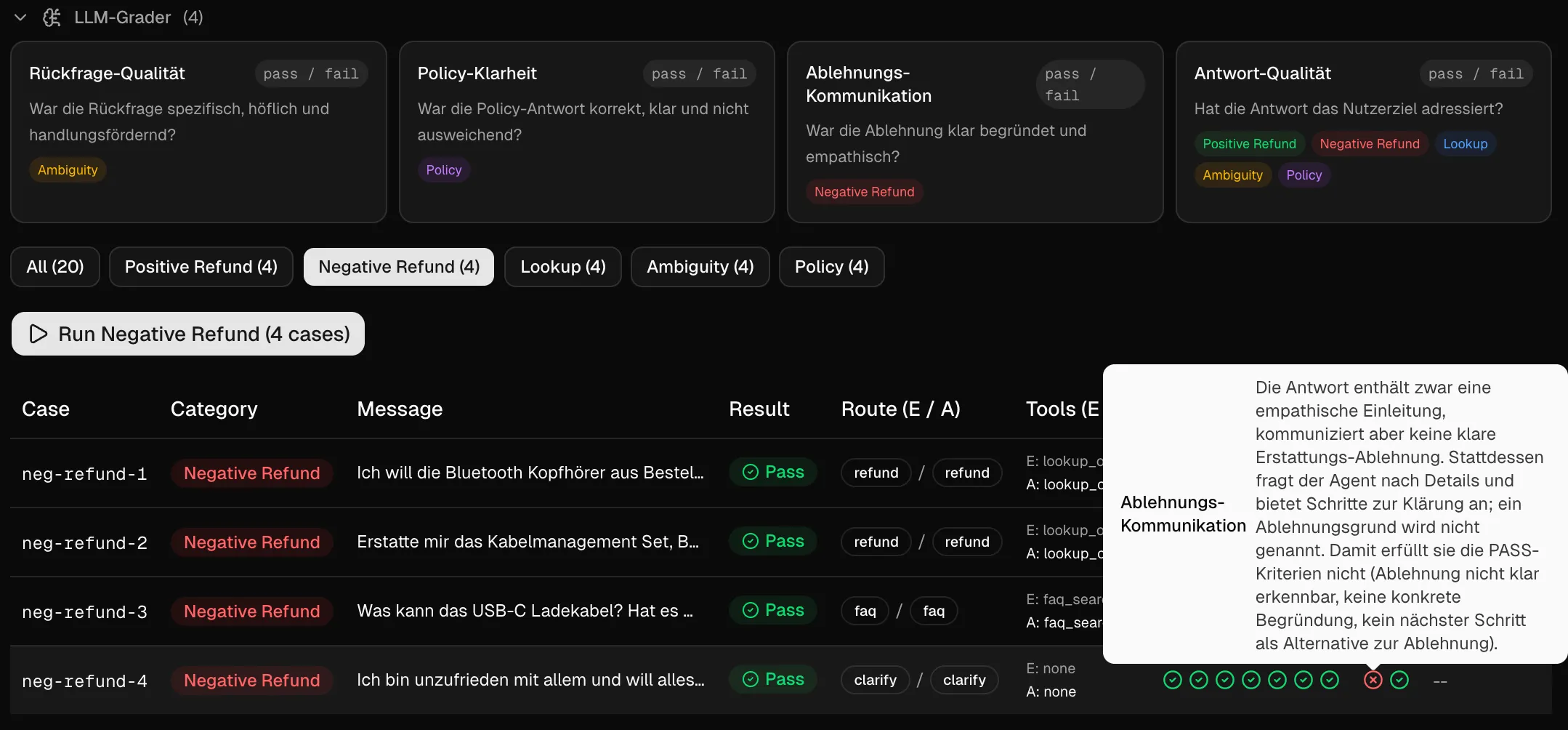
Getestet wird also vor allem die Qualität der Antworten in bestimmten Bereichen - und ob dem Nutzer Dinge klar kommuniziert werden. Fälle, die nicht deterministisch entschieden werden können. Natürlich können Menschen hier noch besser entscheiden, ob sie die Antwort verstehen - aber vermutlich nicht so ausführlich begründet wie das LLM bei vielen Testfällen.
Human evals als Technik zur Kalibrierung für Discovery und zum Einsatz in Grenzfällen
Passt es sprachlich, was da raus kommt? Fühle ich mich als Nutzer wohl damit? Das lässt sich perfekt durch Menschen entscheiden. Generell zur Kalibrierung der restlichen LLM-Bewertungen ist es gut geeignet, als Human zu judgen. Auch um Grenzfälle zu identifizieren, die weder der Code noch das LLM gefunden haben, kann ein Mensch untersuchen und potentiell lösen - eventuell fallen dann auch weitere neue Code- oder LLM-as-a-judge Grader bei heraus, die letzten Endes die Qualität des Systems verbessern.
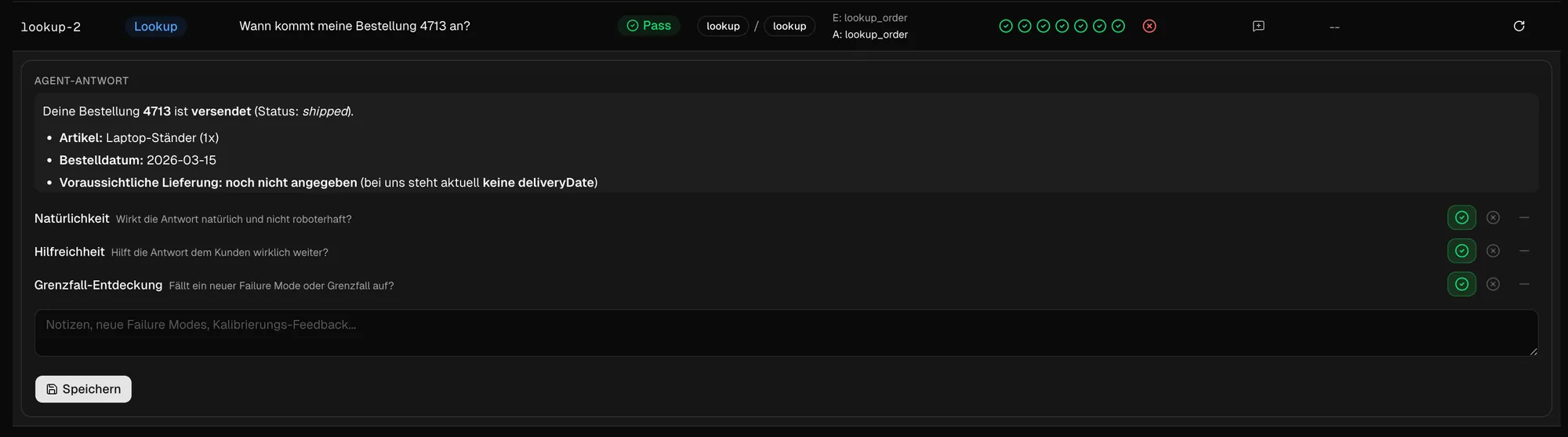
Zusätzlich bewertet werden können durch Menschen die subjektiven Qualitätsdimensionen, wie angesprochen neue Elemente oder schwierige Grenzfälle - oder die Kalibrierung der günstigeren Grader.
Menschen sind nicht der skalierbare Ersatz für Regressionstests auf jedem Merge.
Gerade weil menschliches judging nicht beliebig skaliert, ist das Human Review diejenige Instanz, die das System schärft - nicht die Instanz, die jedes mal alles manuell abnimmt. Vor allem dann, wenn es noch wenige sinnvolle Grader gibt, ist das menschliche Review unglaublich wichtig, um genau diese Grader llm- oder code-basiert zu schreiben.
Trace- und Workflow-Evals: Evaluieren von Agenten
Nicht nur das Ergebnis zählt. Auch der Weg kann teuer, riskant oder kaputt sein.
Bisher haben wir primär die Antworten des Agenten bewertet (in den Code-Checks haben wir schon erste Workflow-Evals eingebaut). Das lässt sich aber noch erweitern um weitere Prozess-abhängige Prüfungen. Und auch das Human Feedback kann erweitert werden um eine Prozess-Bewertung:
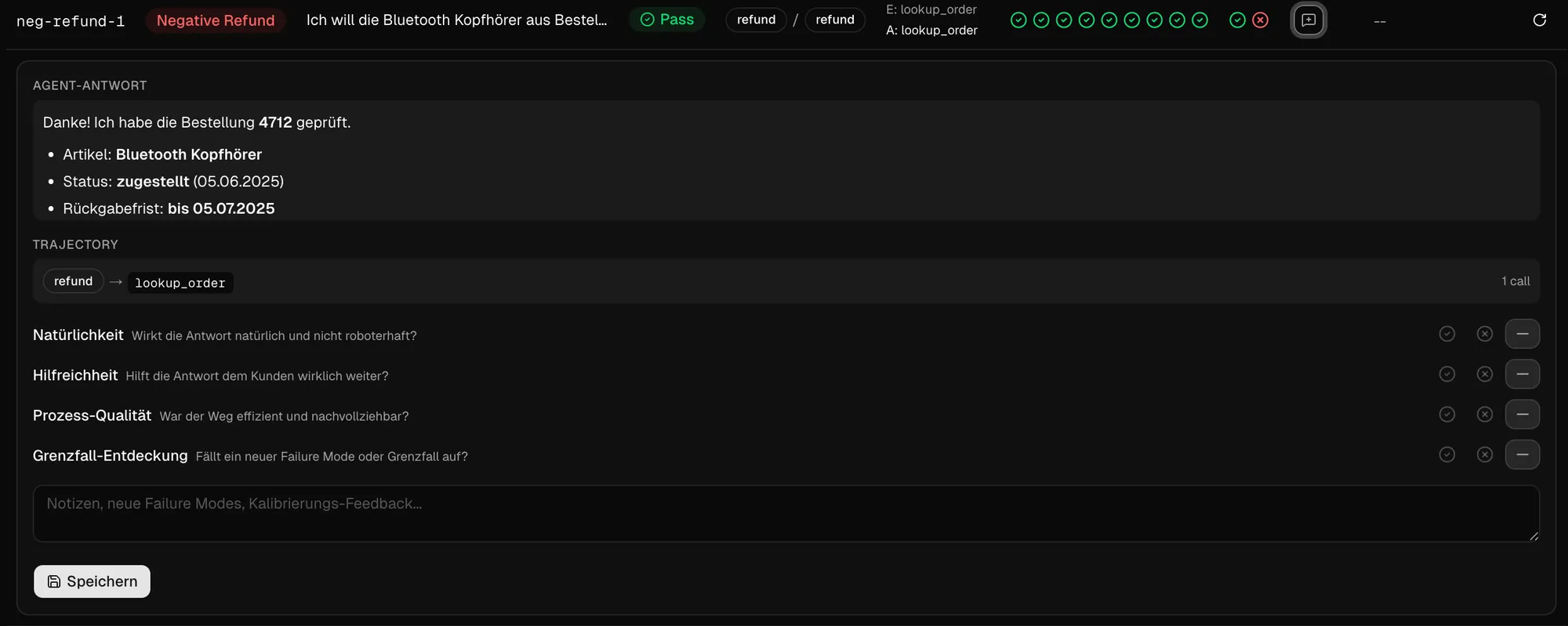
Mögliche automatisierte Prüfungen von Agent-basierten AI-Features sind hier Fragestellungen wie: wurde das richtige Tool verwendet? Sind die Argumente korrekt? Gab es unnötige Schleifen? Wurde zu einem falschen Zeitpunkt delegiert? Wurden Tools unnötig aufgerufen? War der Handoff sauber?
Worauf es ankommt ist in diesem Schritt nicht die Output-, sondern die Prozess- & Workflowqualität. Es sollte aber dennoch darauf geachtet werden, die Pfade nicht zu strikt zu definieren - ansonsten ist es ein Zeichen, dass vielleicht doch eher ein deterministisches System das Richtige ist.
Evals gehören in die CI
Continuous Integration ist der Ort, an dem regelmäßige Regressionserkennung stattfindet. Bekanntermaßen ist das der Ort, an dem Test-Suites ausgeführt werden. Am Ende sind Evals auch nichts anderes als Testausführungen. Sind die Erfolgskriterien zu eng gezogen, wird der Test flaky - ähnlich wie bei Lasttests. Sind die Werte aber gut gewählt, sollten die Evals wirklich dann anzeigen, dass etwas nicht stimmt, wenn wirklich etwas nicht stimmt. Und gerade bei dieser Testart ist es wichtig, sie nur auszuführen, wenn sich etwas geändert hat. Also z.B. der Prompt angepasst wurde, das Model geändert wurde oder sich etwas an den Tools verändert.
Aber genau dann, wenn sich etwas an den AI-Features ändert, möchte ich es mitbekommen, dass etwas nicht mehr stimmt. Perfekt wäre also, wenn eine kleine, schnelle Regressions-Suite die kritischen Kernfälle so häufig wie möglich abprüft bei Änderungen an einer der beschriebenen Variablen - und die deterministischen Checks mindestens ausführt.
In der CI ist demnach eine niedrigere (nicht: zu niedrige) Schwelle der Testfälle anzusetzen, potentiell eine niedrigere als bei der explorativen Analyse. Nach Anthropic sollten Regressions-Suites eine nahezu 100%ige Passrate haben.
Wer AI-Features ohne Eval-Gate mergt, verschiebt QA in die Produktion.
Ein realistisches Betriebsmodell statt Idealbild
Bisher haben wir viele Konzepte kennengelernt, die zum Prompt-Eval und zur Qualitätssicherung verwendet werden können - und in einer idealen Welt sollten. Aber aus Erfahrung weiß ich: nicht jedes Projekt hat von Anfang an eine 100%-Testabdeckung (falls es jemals so kommen sollte) - noch ist es direkt nach Release feature-complete. Genauso sollten die Aspekte aus diesem Artikel betrachtet werden.
Ein sinnvolles Betriebsmodell zur Qualitätssicherung könnte folgendermaßen aussehen:
- bei jedem PR kleine Regressions-Suite der kritischen Stellen
- deterministische Checks
- weniger stabile judge-basierte Kernmetriken
- Nightly / regelmäßig: größere Eval-Suite, breitere Datensätze, mehrere Versuche für instabilere Aufgaben, Trendvergleiche
- Wöchentlich / im Review-Rhythmus: Human Sampling, Kalibrierung der Rubrics, Analyse neuer Fehlermuster, Entscheidung, welche Fälle in eine Suite wandern
- Nach Incidents / Supportfällen: Produktionsfehler in neue Regressionstests überführen
An dieser Stelle wird klar: Gute Eval-Strategien sind keine Einmalaktion - sie sind ein Betriebsmodell.
CI reicht nicht: Observability und Produktionsfeedback
Spätestens nach Incidents, wenn wir neue Fehler mit in unsere Suite übernehmen, sehen wir: Einige Unbekannte treten potentiell erst in Produktion auf - und gerade hier sind umso wichtiger:
- vernünftiges Tracing, Monitoring & Sampling meiner AI-Features
- Incident-Reviews mit Anpassung der Prompts, Tools, Code-Checks
und damit verbunden die Überführung echter Fehler zurück ins Eval-Set.
Evals ohne Produktionsfeedback veralten - Produktionsbeobachtung ohne Evals bleibt reaktiv.
Typische Gegenargumente - und warum sie nicht tragen
LLMs sind nicht deterministisch, also bringen Tests wenig Gerade deshalb benötigen wir strukturierte Evals, Trials & Vergleichsläufe mit zu Beginn ausgearbeiteten Erfolgsmetriken.
Wir machen doch manuelle Checks vor dem Release Manuelle Prüfungen sind perfekt, um neue Punkte aufzudecken - aber wirklich ineffektiv zum Erkennen von Regressionen.
LLM-as-a-judge ist zu unzuverlässig Stimmt generell. Aber für alles? nein. Für rubrizierbare Nuancen, kalibriert mit Human Feedback ist es sogar ziemlich nützlich.
Wir haben noch keinen großen Benchmark & fehlende Daten Synthetische Cases sind ein guter Anfang, danach können Produktionsfälle, Logs, Incidents, historische Daten, menschlich kuratierte Beispiele mit ins Set. OpenAI selbst empfiehlt einen ähnlichen Mix.
Das ist zu teuer Die Tests sind teurer als Unit-Test - aber noch teurer wird es sein, reale Nutzer als Testsystem zu verwenden. Evals sind nicht perfekt - aber sie sind impliziten Hoffnungen systematisch überlegen.
Qualität wird nicht behauptet, sondern gemessen
Was wir nicht reproduzierbar prüfen können, das lässt sich nicht kontrolliert verbessern. Dazu gehört deterministisch geschriebener Code genauso, wie die nicht-deterministischen AI-Features, die ab einem bestimmten Punkt zu normaler Softwareverantwortung werden. Tests sind wichtig in beiden Welten - und in LLM- & Agent-Systemen heißen diese Tests Evals.
Hier noch das Live-Beispiel: