
Die meisten AI-Demos scheitern nicht am Modell. Sie scheitern daran, dass sie Freitext produzieren - obwohl die Anwendung eigentlich Verträge braucht. Sobald ein Modell nicht mehr nur nett in einem Chatfenster antwortet, sondern Produktlogik auslöst, reichen gute Prompts allein nicht mehr.
AI FullStack Engineering beginnt dort, wo Modelloutput zu einem Teil des Systems wird - also dort, wo ich Contract, Auswertung und Observability benötige.
Repo: https://github.com/rubenvitt/plan-from-issue
Fertige Webapp: https://plan-from-issue.pages.dev/
Die Vorbereitung: Unser Beispiel
Um das alles etwas konkreter darzustellen, möchte ich mit einem Beispiel beginnen: eine Mini-Webapp zum Verwandeln eines GitHub Issues oder beliebige Ticket-Texte (z.B. aus Jira, GitLab) in einen strukturierten Umsetzungsplan. Dazu nutze ich zuerst eine Zielstruktur, anhand dessen ein AI-FullStack Feature erklärt wird.
{
"summary": "string",
"affectedAreas": ["frontend", "backend", "database", "infra"],
"risks": ["string"],
"implementationSteps": ["string"],
"testIdeas": ["string"],
"requiresApproval": true
}Basierend auf diesem Beispiel ist es einfach möglich, eine WebApp erstellen zu lassen, die mir mithilfe dieses Zielbildes unterschiedliche Umsetzungspläne sinnvoll darstellen wird - das hat in diesem Fall Claude Code für mich umgesetzt.
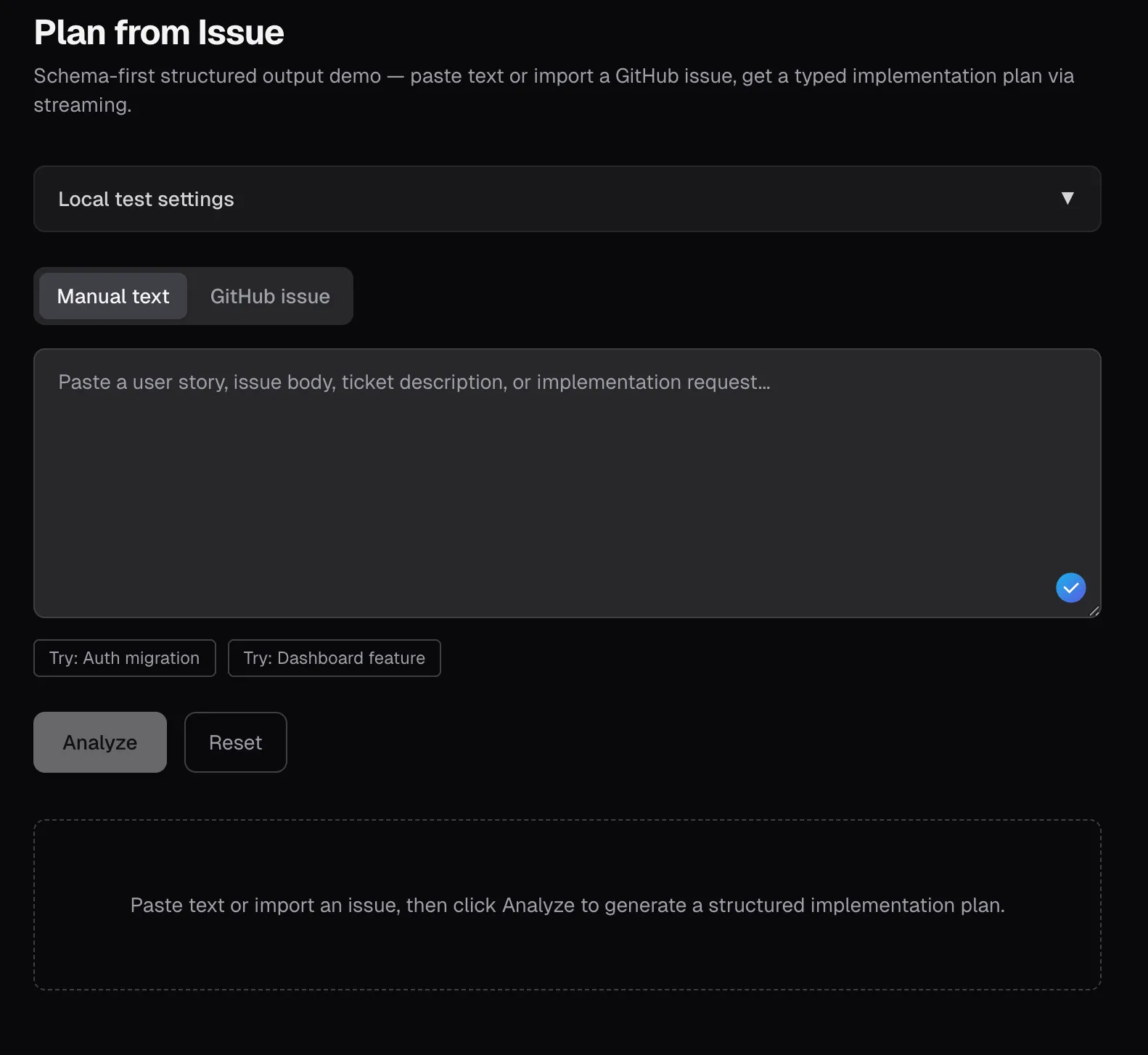
In der erstellten Webapp kann der Nutzer ein Issue in die Textbox eintragen oder über GitHub abrufen - und es strukturiert anzeigen. Klar, das ist ein wirklich einfacher und schnell hergeholter Use Case, dennoch gelten die erläuterten Prinzipien und Konzepte auch für ausgefeiltere UIs - in diesem Fall einfach nachvollziehbar.
Contract-first statt Prompt-first
Mit dem oberen Beispiel habe ich Claude einmal alles erstellen lassen - eigentlich sind wir hier schon fertig. Die App funktioniert (nach einem von ChatGPT erstellten Prompt).
Generierter Prompt zur Erstellung der Demo
You are a senior TypeScript engineer. Build a small but polished demo web app that showcases schema-first AI output using the Vercel AI SDK.
Do not ask follow-up questions. Make reasonable choices and implement the full app end-to-end. Do not leave placeholders or stubs. Keep the code compact, readable, and suitable for a public demo repo / blog post.
Goal
Build a mini web app that turns either:
- freeform story / ticket text
- a GitHub issue
into a structured implementation plan.
The point of the app is to demonstrate that the AI feature is contract-first, not chat-first.
Stack
Use:
- Next.js App Router
- TypeScript
- AI SDK
- AI SDK UI
- Zod
- @ai-sdk/openai
- minimal styling only (simple CSS or Tailwind is fine)
- no database
- no authentication system
- no server-side persistence
Non-negotiable AI SDK architecture
Use these exact patterns:
- shared Zod schema imported by both client and server
- streamText + Output.object(…) in the route handler
- experimental_useObject on the client
- createOpenAI(…) to instantiate the provider with a request-specific API key
- custom request headers from the client to the analyze route
- no plain-text fallback mode for the main analysis flow
- do not use useChat for the main experience
This app is object-generation first, not chat first.
Core JSON contract
The app must use this exact top-level JSON shape and these exact property names:
{ "summary": "string", "affectedAreas": ["frontend", "backend", "database", "infra"], "risks": ["string"], "implementationSteps": ["string"], "testIdeas": ["string"], "requiresApproval": true }Implement it as a shared Zod schema and export the inferred TypeScript type.
Schema requirements:
- summary: non-empty string
- affectedAreas: non-empty array of unique enum values, restricted to: frontend, backend, database, infra
- risks: array of strings
- implementationSteps: non-empty array of strings
- testIdeas: non-empty array of strings
- requiresApproval: boolean
Do not parse model text with regex. Do not accept “almost matching” output. The UI and server must rely on schema-validated structured output.
Gehen wir aber nochmal ein paar Schritte zurück. Im Normalfall baue ich nicht etwas, nur um es mit AI befüllen. Stattdessen sollen meine Daten aufbereitet und intelligent in die UI integriert werden. Dazu gibt es bereits unzählige Artikel im Internet und AI hilft mir hier schon perfekt.
Der Kernpunkt ist allerdings: zuerst kommt der Contract, dann der Prompt. Ich muss wissen, welche Daten ich strukturiert extrahieren muss, bevor ich ans Schreiben und Perfektionieren meines Prompts übergehe. Dazu gilt es, Engineering-Arbeit zu listen, wie sie auch schon in der Prä-AI Ära bekannt sein sollte.
- Welche Felder möchte ich aus den unstrukturierten Daten extrahieren?
- Welche Felder sind Pflicht? Welche Optional?
- Welche Wertebereiche gelten für Zahlen & Strings? Gibt es Enums?
- An welchen Stellen sollte ich Output begrenzen, damit der Output in der UI oder Pipeline brauchbar bleibt?
Dabei helfen mir je nach gewählter Programmiersprache unterschiedliche Frameworks. Denken wir an eine der moderneren Entwicklungsumgebungen (TypeScript), so könnte beispielsweise ai-sdk in Betracht gezogen werden. Aber auch Java wird mit Spring AI bedient, andere Programmiersprachen bringen sicherlich ähnliches Tooling mit. Diese Frameworks helfen, die Kommunikation zu unterschiedlichen Model Providern zu vereinheitlichen, sodass ich mich nicht direkt an Hersteller und deren APIs binden muss. In diesem Artikel konzentriere ich mich auf TypeScript & ai-sdk.
Solche Frameworks bieten den großen Vorteil, dass sie die APIs der einzelnen Anbieter vereinheitlichen und typische Funktionen einfach und äquivalent konfigurierbar halten - so z.B. structured outputs, genau das, was wir benötigen.
Um diesen Contract zu konstruieren, wird meist ein Contract - vor allem JSON-Schema - benötigt. JSON-Schema beschreiben den Contract für JSONs: welche Pflichtfelder gibt es? Welchen Regex müssen diese Werte einhalten? Zahlenbereiche etc. - um dieses JSON-Schema zu erstellen oder zu validieren können wir Tools wie https://json.ophir.dev/ verwenden. Oder AI fragen, ob sie uns ein passendes JSON-Schema nach unseren Bedürfnissen erstellt.
Der wichtigste Teil meines AI-Features ist nicht der Prompt, sondern der Vertrag, den der Rest der Anwendung von der Modellantwort erwartet.
Mit dem generierten oder erstellten Contract im Gepäck können wir uns aufmachen, einen passenden Prompt zu formulieren. Die Antwort wird sicherlich entweder dem Contract entsprechen - oder einem Fehler-Contract, den wir gesondert behandeln müssen, z.B. refusal von OpenAI.
Evals statt Bauchgefühl
Wer ein AI-Feature ohne Evals baut, testet am Nutzer.
Wie oben beschrieben, hat mir Claude mit einem Shot direkt eine funktionierende Webapp gebaut, wenn ich als Beispiel das issue https://github.com/rubenvitt/bluelight-hub/issues/420 eintrage, erhalte ich strukturierten Output:
{
"summary": "Implement a Verpflegungsmanagement feature under the Betreuung area to manage feeding locations, meal planning, and distribution tracking for Einsatzkräfte and Betroffene. The change includes frontend views on the specified route and backend CRUD plus integrations for planning quantities and recording consumption.",
"affectedAreas": [
"frontend",
"backend"
],
"risks": [
"Integration dependencies on Kräfte-, Betroffene-, Logistik-Modul, and Lagekarte may block parts of the feature or require fallback handling.",
"Quantity estimation can become inconsistent if personnel and affected-person counts are unavailable, delayed, or separated differently than expected.",
"Tracking meal status and portion counts across multiple Ausgabestellen introduces risk of incorrect state transitions or double counting.",
"Capturing Sonderbedürfnisse must stay usable in the UI while still being detailed enough for planning."
],
"implementationSteps": [
"Add backend CRUD support for Verpflegungsstellen with fields for name, location, type, capacity, opening/output times, and responsible personnel.",
"Add backend CRUD support for Mahlzeiten including time, type, estimated quantity, assigned Ausgabe-/Verpflegungsstelle, separated counts for Einsatzkräfte and Betroffene, Sonderbedürfnisse, and status values Geplant, In Zubereitung, Ausgabe, Abgeschlossen.",
"Implement backend logic for quantity estimation based on the provided formula using counts from Kräfte and Betroffene where available.",
"Add backend endpoints or service integration for recording consumption data per Mahlzeit and Ausgabe-/Verpflegungsstelle: issued portions, beverage consumption, remaining quantities, and material consumption for Logistik handoff.",
"Build the frontend page at /app/einsatz/$einsatzId/betreuung/verpflegung with management views for Verpflegungsstellen and Mahlzeiten.",
"Implement Verpflegungsstellen cards showing key details and current status, with create/edit/delete flows.",
"Implement a Mahlzeiten timeline that separates planned, current, and past meals and supports status updates through the defined lifecycle.",
"Add meal planning UI for time, type, quantity estimate, separated person counts, special needs, and assigned distribution point.",
"Implement quick-entry controls for portion output using +/- counters and forms for beverage usage and remaining quantities.",
"Add a dashboard view showing supply coverage as x% versorgt based on planned vs. served data.",
"Integrate map marking of Verpflegungsstellen on the Lagekarte from the route workflow.",
"Connect quantity planning to personnel counts from Kräfte and affected-person counts from Betroffene, and send recorded material consumption to Logistik for replenishment workflows."
],
"testIdeas": [
"Create, update, list, and delete Verpflegungsstellen with all required fields and verify they appear correctly in the management UI.",
"Plan a Mahlzeit with separated counts for Einsatzkräfte and Betroffene and verify the estimated quantity follows the specified calculation.",
"Verify meal status transitions from Geplant to In Zubereitung to Ausgabe to Abgeschlossen are reflected correctly in the timeline and detail views.",
"Record portion output for a meal at a specific Verpflegungsstelle with +/- quick entry and confirm totals persist correctly.",
"Record beverage consumption, remaining quantities, and material consumption and verify the data is stored and associated with the correct meal and location.",
"Enter Sonderbedürfnisse such as allergies, vegetarian, halal, and confirm they are retained and visible in planning views.",
"Verify Verpflegungsstellen are shown on the Lagekarte with the configured location.",
"Test integration behavior when Kräfte or Betroffene counts are available versus unavailable, ensuring quantity estimation degrades predictably.",
"Verify the dashboard coverage percentage updates as portions are issued.",
"Confirm material consumption data is handed off correctly to the Logistik integration path."
],
"requiresApproval": false
}40 Zeilen Ergebnis. LGTM. Done.
Oder… nicht?
Die Frage ist nicht, ob die Antwort “smart” klingt, sondern ob sie für meinen Workflow verlässlich genug ist.
Woher weiß ich, dass das Ergebnis ein gutes Ergebnis ist? Woher weiß ich, dass ich darauf vertrauen kann? Der Contract gibt mir eine strukturelle Garantie. Ob der Inhalt fachlich taugt, ist damit noch nicht beantwortet. Deshalb sind vor allem die fachlichen Fragen zu klären: Sind die betroffenen Bereiche sinnvoll erkannt? Sind die Risiken brauchbar? Kann ich die Testideen wirklich verwerten - oder ist das unnötiger Nonsense? Ist das Approval-Flag plausibel? Eine Option, diese Fragen in Gänze zu beantworten ist es, durch jede einzelne Antwort durchzugehen - und diese Fragen für mich selbst zu beantworten, zu bewerten. Dann kann ich den Prompt anpassen und erneut bewerten. Aber meine ehrliche Meinung dazu? Das möchte ich nicht, nein! Ich habe keine Lust dazu.
Und ja, es gibt eine Alternative. Sogar einige. OpenAI hat einen eigenen Optimizer, es gibt aber auch zahlreiche Open Source Tools. Ein Beispiel dafür wäre https://github.com/promptfoo/promptfoo.
Zur einfachen Darstellung habe ich mich hier für die OpenAI Platform entschieden. Dort ist eine Evaluierung schnell gemacht: Prompt erstellen (wichtig: mit Variable!), im Reiter Evaluation ein neues dataset anlegen, dann Testdaten einfügen. Ich nehme mir einfach einige meiner issues aus dem bluelight-hub Projekt - anschließend auf play klicken, schon wird der Prompt auf die Liste an Inputs ausgeführt (achtung: kostet Geld).
Hier unterstützt uns OpenAI schon sehr, fast alles kann dort direkt automatisch überarbeitet werden, auch unser JSON Schema kann generiert werden. Ich habe einfach mal das zod-Schema aus dem Beispielprojekt dort eingefügt - dann wurde das passende JSON Schema dazu generiert…. perfekt.
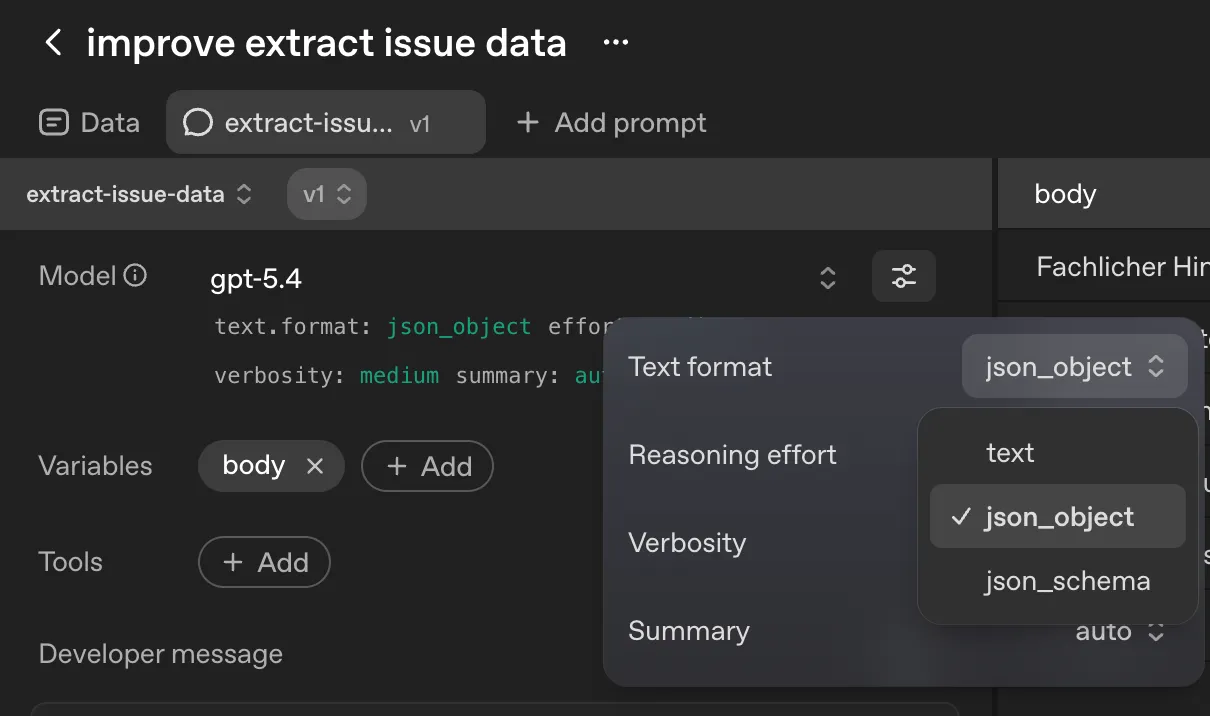
Der Vorteil daran? Wir haben nun mehrere Spalten in unserer Eval-Ansicht und können die einzeln produzierten Werte direkt ablesen und prüfen, wie wir damit umgehen wollen.
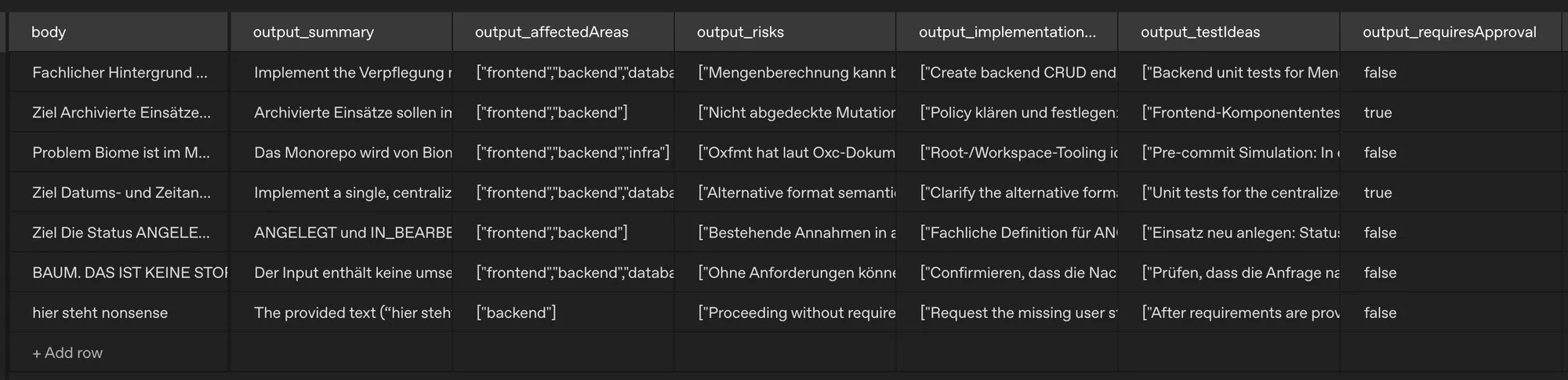
Nun können wir mit der eigentlichen Evaluierung beginnen: Neue Columns anlegen für entweder manuelle Begutachtung (annotation) - oder wir lassen die AI die einzelnen Antworten begutachten (grader), prüfen und bewerten; nach unseren Kriterien.
Nach einer ersten Evaluation nach zwei Kriterien wird deutlich: unser Prompt benötigt etwas Nacharbeit. Was ist zu tun? In diesem Tool genügt ein Klick auf Optimize - und OpenAI kümmert sich um den Rest - basierend auf der Bewertung aus der Prompt Evaluation.
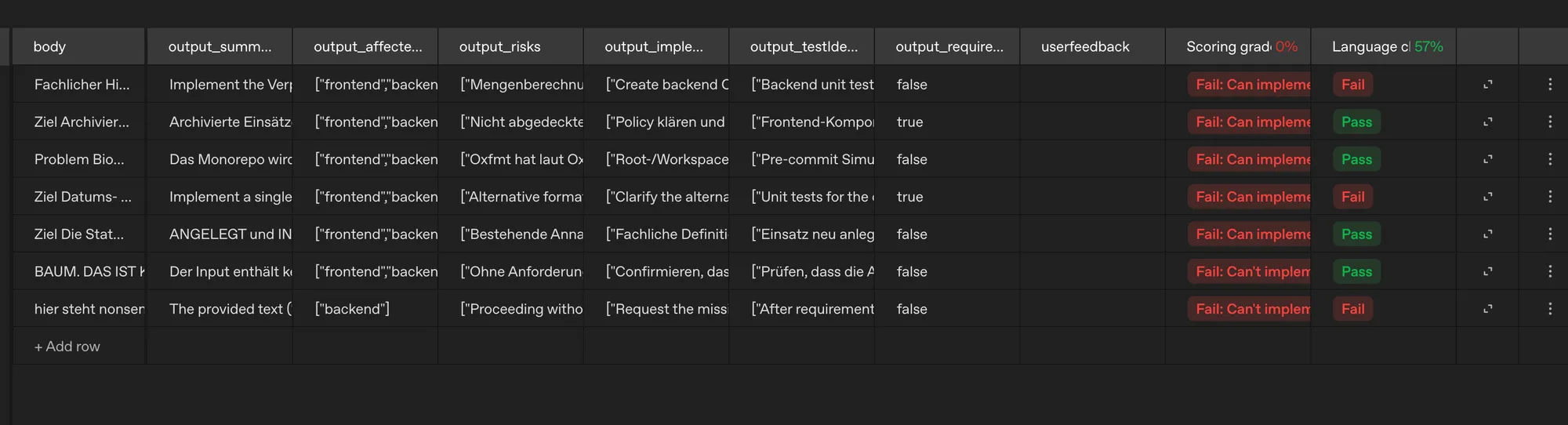
Nach ein bisschen weiterer Optimierung und einer manuellen Anpassung (per Prompt) ist das Ergebnis dann ein bisschen besser geworden. Klar, das ist ein wirklich kleines Set zur Evaluierung - mir geht es hier eher um die Sache an sich; auch manuelles Feedback habe ich hier einfach mal ausgelassen, auch wenn das in normalen Fällen dazu gehört, um letzten Endes sinnvolle Ergebnisse zu erhalten.
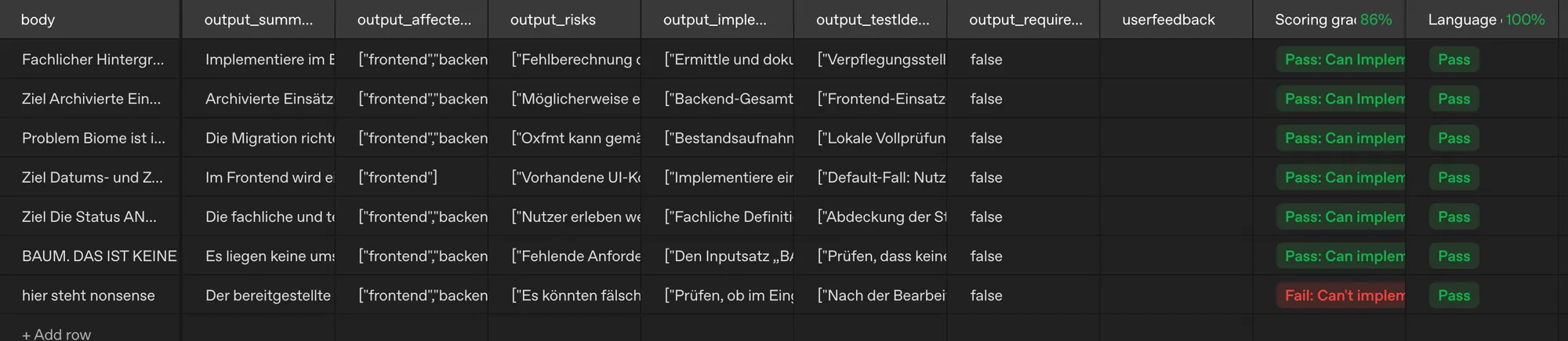
Mit dem tollen Ergebnis gehe ich direkt zu Claude und bitte darum, den Prompt mit dem erstellten zu aktualisieren.
Damit haben wir jetzt einen verbesserten Prompt, der unsere Anforderungen besser abdeckt. Mit dem structured output erstellen wir UI, statt reinem Text-output. Soviel zum Mini-Einblick. Hier gibt es noch so viel mehr zu entdecken, zu optimieren und verfeinern.
Das Grundprinzip der Eval sollte aber dennoch klar geworden sein: Ziele definieren, Datensatz sammeln aus Beispielen, eventuell erwarteten Ergebnissen, Metriken festlegen, Läufe vergleichen, auswerten lassen.
Observability statt Black Box
Wenn wir nichtdeterministische Systeme in unsere Anwendungen implementieren, ist es umso wichtiger zu verstehen, was geschah, wenn es mal kaputt ist, um eine Möglichkeit zu finden genau das zu mitigieren. Dazu gehören einige wichtige Datenpunkte, die wir bestenfalls sammeln wollen:
- welches Modell wurde genutzt?
- wie lange hat das LLM für eine Antwort benötigt?
- war das zurückgegebene JSON valide zum Contract?
- waren Retries nötig?
- ggf.: welche Tools wurden genutzt?
- wo mussten Menschen eingreifen?
- wie viele Token wurden genutzt und wie hoch waren die damit verbundenen Kosten?
OpenTelemetry führt inzwischen Konventionen für GenAI Applications für Events, Metriken & Spans. Das bedeutet, auch die AI Funktionen können ins Observability eingebunden werden. Im oben erwähnten AI SDK existiert ebenfalls ein Konnektor, um über das Framework automatisiert entsprechende Daten aufzunehmen und zu versenden.
Der FullStack-Teil ist die UI, nicht nur das Modell
FullStack wird das Thema erst dann, wenn ich nicht nur ein Modell anspreche, sondern einen Bedienfluss für Menschen entwerfe.
Nachdem wir nun einen vernünftigen Contract mit dem LLM ausgemacht haben, den über die API kommunizieren, einen wirklich tollen Prompt gebaut haben, was fehlt? Klar, die UI. Zu Anfang des Posts habe ich schon angedeutet: allein ein bisschen Text anzuzeigen, das kann jeder. Auch nach dem One-Shot Versuch mit Claude war es zwar kein Chat-Interface, aber dennoch nur eine Aneinanderreihung an Texten. Jetzt bewegen wir uns zwar in etwas trockenem Territorium - einem Umsetzungsplan für Stories, aber zumindest für die Darstellung bekommen wir doch bestimmt etwas tolles hin, oder?
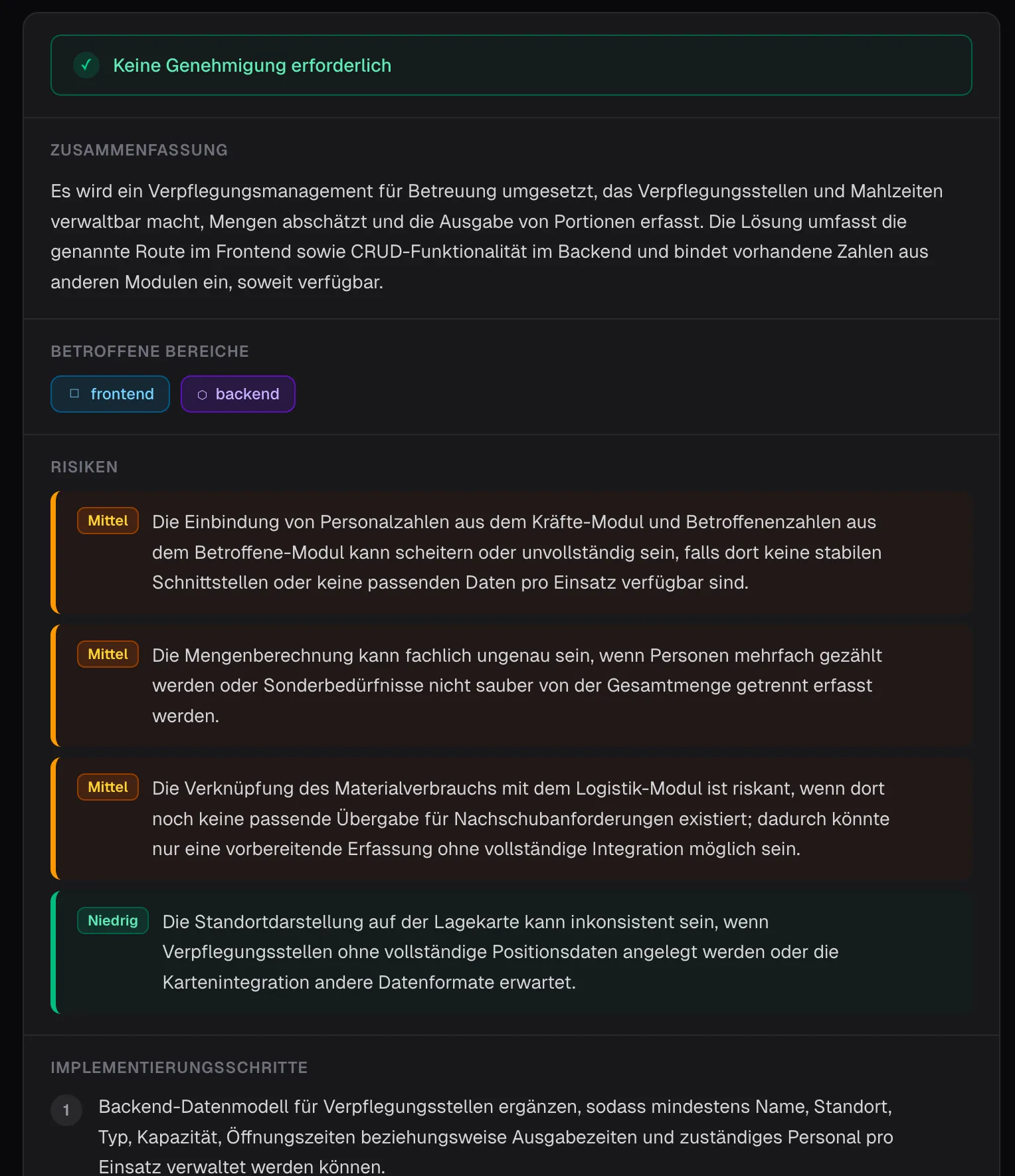
Im ersten Schritt wollte ich, dass die Daten einfach etwas schöner aufbereitet werden. So weit so gut, wie wäre es dann mit einem Umsetzungs-Canvas?
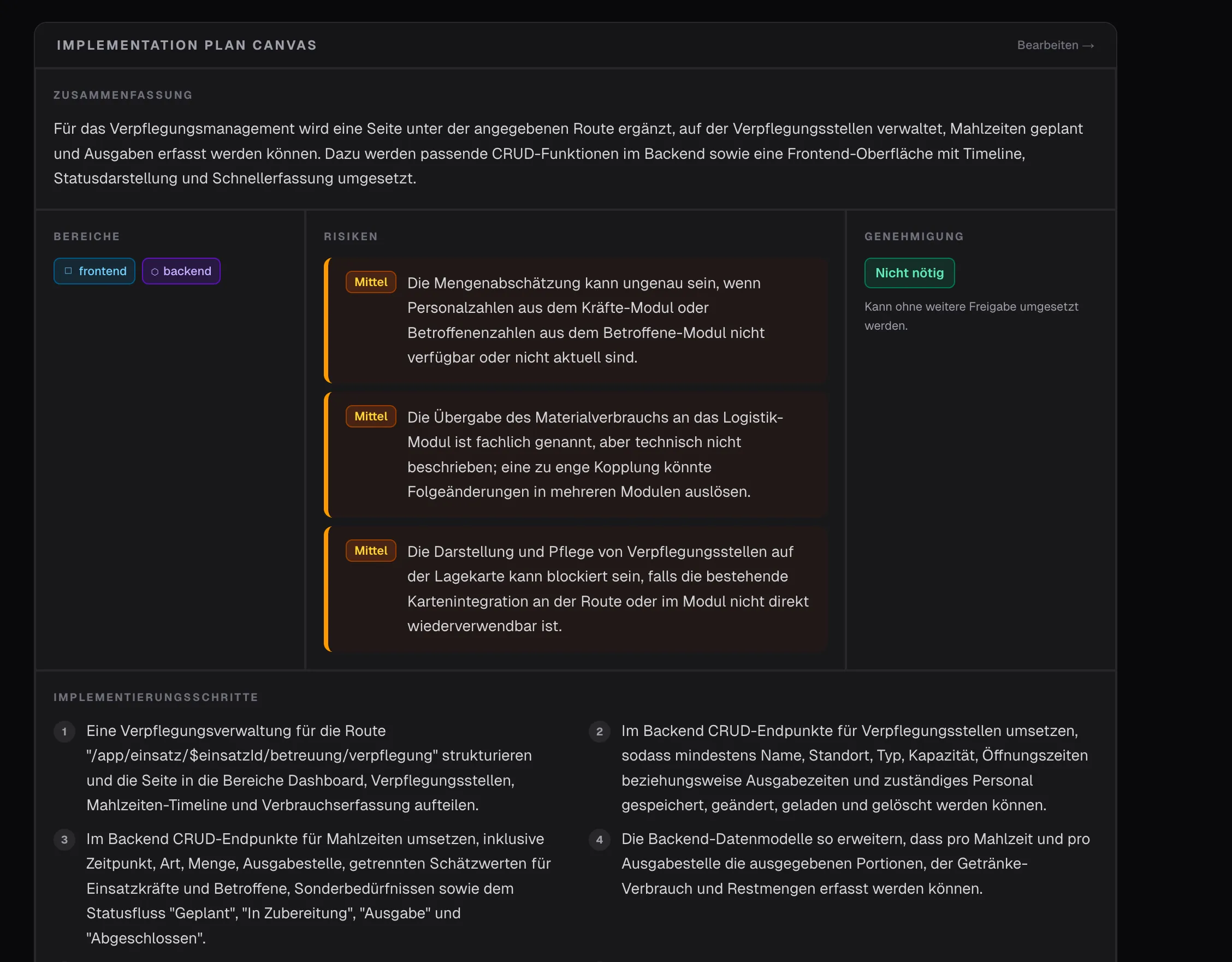
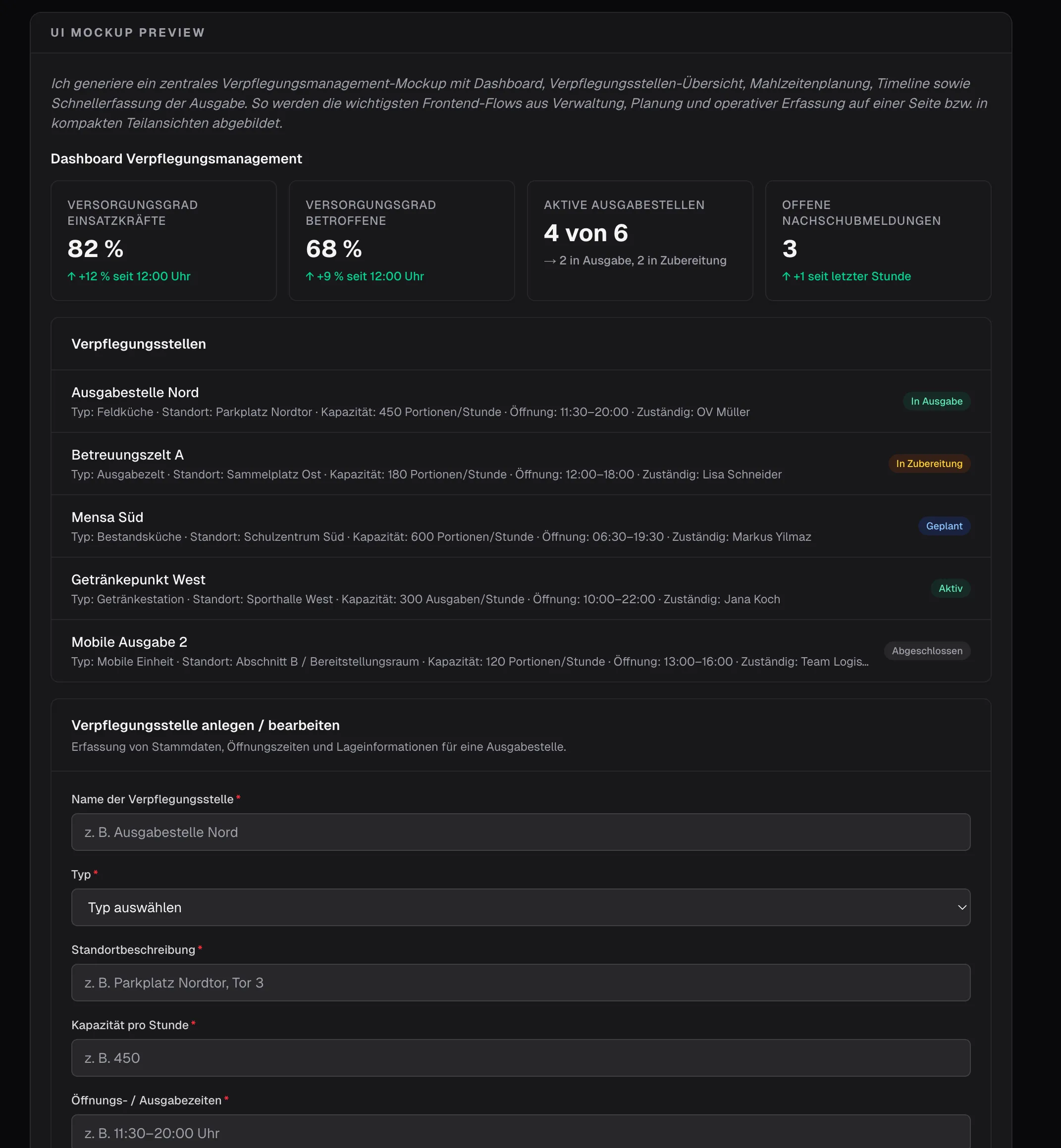
Eine weitere Art der Anzeige - mit der Option die Inhalte zu bearbeiten - aber wie können wir wirklichen Mehrwert schaffen? Wenn der Task Frontend-Arbeit beinhaltet… sollten wir dann nicht direkt ein Mockup erzeugen? Gesagt, getan…
Ohh, I love Agentic Engineering.
Prompt Engineering bleibt nützlich. Aber sobald Modelloutput echte Produktlogik trägt, benötige ich vor allem drei Dinge: Contracts, Evals und Telemetrie. Genau dort beginnt für mich AI Systems Engineering. Und im Entdecken neuer Interaktionsmuster.