
Je autonomer ein Agent wird, desto wichtiger wird die Qualität der menschlichen Eingriffspunkte - nicht deren Abschaffung.
Ein Kunde möchte eine Erstattung. Der Refund-Agent schlägt refund_order vor, die Parameter stimmen, die Berechtigung ist geprüft. Und dann: ein Approval-Banner. Der Workflow pausiert. Nichts passiert, bis ein Mensch auf “Bestätigen” klickt.
Der erste Reflex? “Warum kann er das nicht einfach machen?”
Ich kenne diesen Reflex. Wir bauen Agents, damit sie Dinge für uns erledigen - und dann stellen wir ihnen ein Stoppschild in den Weg. Das fühlt sich an wie Friction. Wie ein Rückschritt. Wie das Gegenteil von Automatisierung. Nur: refund_order bewegt Geld. Echtes Geld. Und ein Agent, der autonom Geld bewegen kann, ist kein Feature - er ist ein Risiko.
Das requiresApproval: true im Tool-Catalog des Refund-Agents ist kein Zufall. Es ist eine architektonische Entscheidung - im vorherigen Post habe ich das Policy Gate als Teil der “Definition of Done” für Agent-Tools eingeführt. Dort war require_approval ein Punkt unter vielen. Hier wird es zum zentralen Thema.

Pause ist kein Bug, sondern Governance
Ein Approval-Punkt in einem Agent-System folgt einem einfachen Prinzip: Der Agent schlägt vor, der Mensch entscheidet, das System führt aus. Drei Schritte, klare Verantwortung. Das klingt nach Overhead - ist aber Architektur.
Wichtig ist die Abgrenzung zweier Konzepte, die oft vermischt werden: Elicitation und Governance Gates. Elicitation bedeutet, dass der Agent aktiv nach Informationen fragt - “Welche Bestellnummer meinst du?” oder “Soll ich den Testbericht als PDF oder Markdown generieren?”. Der Agent braucht Input, um weiterzuarbeiten. Ein Governance Gate ist etwas anderes: Das System erzwingt eine Freigabe, bevor eine irreversible Aktion ausgeführt wird. Nicht weil der Agent unsicher ist, sondern weil die Aktion es erfordert.
Elicitation ist UX. Governance ist Sicherheitsarchitektur.
Die Analogie zu Pull Request Reviews hilft: Ja, PR-Reviews kosten Zeit. Ja, sie sind ein Bottleneck. Und trotzdem sind sie in fast jedem professionellen Team Standard - weil der Schaden durch unkontrollierten Code in Produktion den Overhead überwiegt. Approval-Gates bei Agents sind dasselbe Prinzip: ein erzwungener Haltepunkt vor einer Zustandsänderung, die sich nicht einfach rückgängig machen lässt.
Anthropics Analyse zu Claude Code liefert dazu eine interessante Beobachtung: Das Modell pausiert in über 16 % der komplexen Turns selbstständig - mehr als doppelt so häufig, wie Menschen den Agent unterbrechen (rund 7 %). Das Modell erkennt seine eigene Unsicherheit und handelt danach. Es wartet nicht darauf, gestoppt zu werden - es stoppt sich selbst.
Anthropics “Building Effective Agents” empfiehlt genau das: Agents sollen bei Checkpoints pausieren und auf menschliches Feedback warten können. Die dahinterliegende Philosophie lässt sich auf ein Prinzip verdichten, das ich für zentral halte - Least Agency: Gib dem Agent nur so viel Autonomie, wie die Aufgabe tatsächlich erfordert. Nicht mehr.
Wer in meinem Post zu Evals genau hingeschaut hat, erinnert sich vielleicht: Im Contract stand explizit User-Approval: Der Workflow sollte pausieren - als bewusste Design-Entscheidung, nicht als Notlösung.

Pause/Resume ist für Agent-Systeme, was Pull Request Reviews für Code sind: nicht optional, sondern Qualitätssicherung.
Wann Approval Pflicht ist - und wann nicht
Nicht jede Agent-Aktion braucht einen Menschen. lookup_order abzunicken wäre absurd. Aber refund_order ohne Freigabe durchlaufen zu lassen wäre fahrlässig. Die Frage ist nicht binär - sie ist ein Stufenmodell.
| Risiko-Stufe | Beispiel | Aktion |
|---|---|---|
| Read-Only | lookup_order, faq_search |
Auto-Allow |
| Low-Risk Mutation | reset_password |
Loggen, kein Approval |
| High-Risk Mutation | refund_order |
Approval erforderlich |
| Irreversibel | delete_account |
Approval + 4-Augen-Prinzip |
Read-Only ist unkritisch - der Agent liest Daten, verändert aber keinen Zustand. Hier bremst ein Approval-Gate nur den Flow, ohne Sicherheit zu gewinnen. Low-Risk Mutations verändern Zustand, aber die Auswirkung ist begrenzt und umkehrbar. Ein neues Passwort kann der User selbst zurücksetzen. Loggen reicht, damit der Audit-Trail vollständig bleibt. High-Risk Mutations bewegen Geld, ändern Verträge oder betreffen sensible Daten - hier muss ein Mensch explizit freigeben, bevor das System ausführt. Und irreversible Aktionen wie Account-Löschungen brauchen nicht nur Approval, sondern ein 4-Augen-Prinzip: Eine zweite Person bestätigt, was die erste freigegeben hat.
Die Zuordnung ist keine Wissenschaft - sie ist eine bewusste Produkt-Entscheidung. Im Refund-Agent sieht das konkret so aus:
Refund-Agent Tool-Zuordnung: lookup_order und verify_customer laufen ohne Approval durch - reine Lesezugriffe. faq_search ebenso. refund_order ist requiresApproval: true und isDestructive: true - hier pausiert der Workflow. Interessant: reset_password ist als isDestructive: true markiert, braucht aber kein Approval. Eine bewusste Design-Entscheidung - und in der Contracts-UI per Toggle jederzeit änderbar.
Dieses Stufenmodell ist kein theoretisches Framework. Es wird ab August 2026 auch regulatorisch relevant.
EU AI Act Art. 14: Fünf Pflicht-Fähigkeiten ab 2. August 2026
Der EU AI Act schreibt für High-Risk-Systeme fünf konkrete Human-Oversight-Fähigkeiten vor:
- Verstehen & Überwachen - Kapazitäten, Limitierungen und Anomalie-Erkennung (Art. 14(4)(a))
- Automation Bias Awareness - Bewusstsein für Über-Vertrauen in AI-Output (Art. 14(4)(b))
- Output korrekt interpretieren - mittels Interpretations-Tools (Art. 14(4)(c))
- Override oder Reverse - jede AI-Entscheidung umkehren oder ignorieren können (Art. 14(4)(d))
- Eingreifen oder Stoppen - Safe-Halt via Stop-Button o.Ä. (Art. 14(4)(e))
Bemerkenswert: Art. 14(4)(b) adressiert explizit Automation Bias - Behavioral Science in Hard Law. Bei Verstößen drohen bis zu 15 Mio. EUR oder 3% des globalen Jahresumsatzes.
Nicht jede Aktion braucht einen Menschen. Aber jede risikoreiche Aktion braucht die Möglichkeit eines Menschen. Und die muss architektonisch vorgesehen sein - nicht nachträglich drangeschraubt.
Wie ein Approval-Flow technisch funktioniert
Vom Stufenmodell zur Implementierung. Das grundlegende Pattern ist überraschend simpel - die Komplexität liegt woanders, als die meisten denken.
Das Pattern
Jeder Approval-Flow folgt demselben Ablauf: Der Agent formuliert einen Tool-Intent. Ein Policy Gate prüft, ob dieser Intent eine Genehmigung erfordert. Falls ja, pausiert die Execution, der Intent landet in einer Approval Queue, ein Mensch entscheidet - und erst dann wird der Tool-Call tatsächlich ausgeführt. Oder eben nicht.
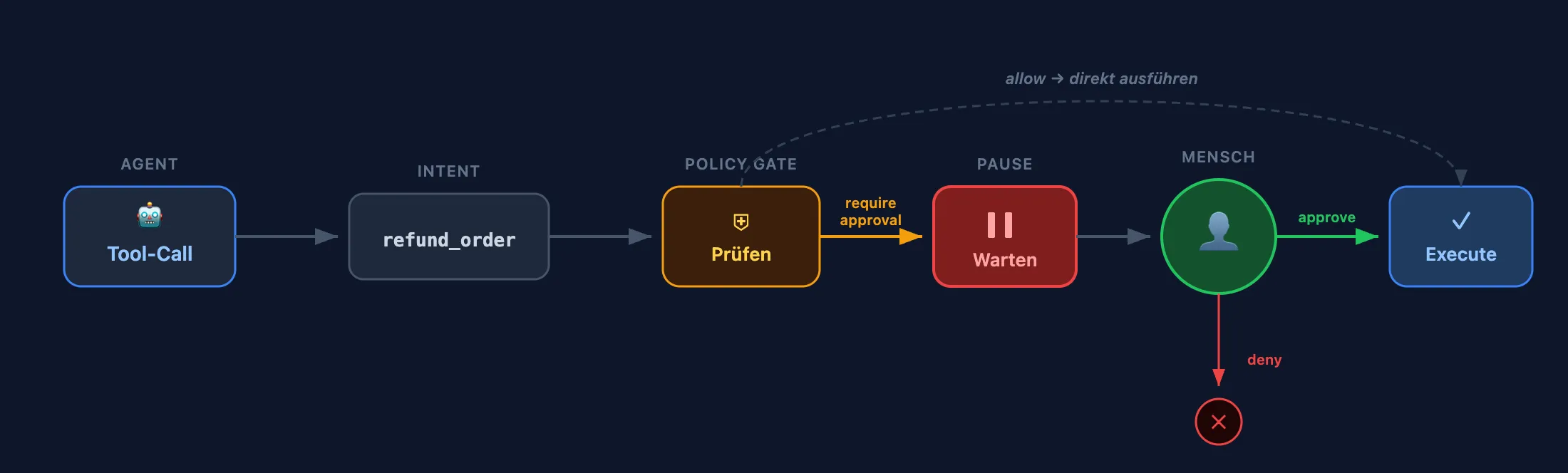
In Code ist das erstaunlich wenig Aufwand. Im Vercel AI SDK reicht ein einziges Flag auf der Tool-Definition:
const refundOrder = tool({
description: 'Process a refund for an order',
parameters: z.object({
orderId: z.string(),
reason: z.string(),
}),
needsApproval: true,
execute: async ({ orderId, reason }) => {
return await processRefund(orderId, reason);
},
});needsApproval: true - das ist alles. Der Server wartet, bis der Client über addToolApprovalResponse eine Entscheidung sendet. Approved? Der Tool-Call wird ausgeführt. Denied? Der Agent bekommt die Ablehnung als Kontext und kann reagieren.
Die eigentliche Herausforderung liegt nicht im Pattern selbst, sondern in dem, was drumherum passieren muss: State Persistence, Crash Recovery, und die Frage, was mit einem Approval passiert, das erst nach drei Stunden kommt.
SDK-Vergleich
| Dimension | Vercel AI SDK | OpenAI Agents SDK | LangGraph | Temporal |
|---|---|---|---|---|
| Pause-Mechanismus | needsApproval auf Tool |
needs_approval auf Tool |
interrupt() in Node |
workflow.wait_condition() |
| State-Persistenz | Client-State (React) | Explizit via RunState.to_json() |
Automatischer Checkpointer | Automatische Event History |
| Crash Recovery | Session-abhängig | Manuell (Rehydrate aus DB) | Checkpointer-abhängig | Vollautomatisches Replay |
| Best Fit | React/Next.js Chat-UIs | Leichtgewichtige Agent-Tools | Graph-basierte Workflows | Enterprise Long-Running |
Vercel und OpenAI setzen auf deklarative Flags direkt am Tool - der einfachste Einstieg. LangGraph checkpointet automatisch, aber Code vor einem interrupt() muss idempotent sein, weil die gesamte Node bei Resume von vorne läuft. Temporal spielt in einer anderen Liga: praktisch unbegrenzte Wartezeit, vollautomatisches Replay bei Crash, Signals für externe Entscheidungen.
Approval mit dem OpenAI Agents SDK (Python)
result = await Runner.run(agent, "Delete temp files no longer needed.")
if result.interruptions:
state = result.to_state()
serialized = state.to_json() # persist to DB for async approval
# ... later, after human decision ...
state = RunState.from_json(agent, serialized)
state.approve(result.interruptions[0])
result = await Runner.run(agent, state)Auch MCP liefert inzwischen ein relevantes Primitiv: Elicitation erlaubt es einem MCP-Server, während der Tool-Execution auf User-Input zu warten - primär für fehlende Informationen, nicht für Governance. Aber das zugrundeliegende Pause/Resume-Muster (accept, decline, cancel) ist dasselbe. Ein standardisiertes Governance-Gate-Protokoll fehlt in MCP noch - das Primitiv dafür ist aber da.
Was der Approver sehen muss
Technisch funktioniert das alles. Aber ein Approval-Flow ist nur so gut wie die Information, die der Approver bekommt. Wer will was, auf welchem Objekt, warum, mit welchem Risiko - das muss auf einen Blick erfassbar sein. Nicht der gesamte Chat-Verlauf, nicht jeder Zwischenschritt der Agent-Konversation. Sondern eine komprimierte Entscheidungsgrundlage.
Im Refund-Agent sieht das so aus: Ein Approval-Banner zeigt Tool-Name und Argumente als JSON. Approve oder Deny. Und jede Entscheidung wird Teil eines strukturierten Audit-Trails - mit Actor, Subject, approvalOutcome, approvalId und Prompt-Version-Hash.
Der Approval-Flow ist kein technisches Problem. Er ist ein Produkt-Problem: Was braucht ein Mensch, um in drei Sekunden die richtige Entscheidung zu treffen?
Durable Execution
In der Demo reicht Session State. In Produktion nicht. Approvals, die Stunden oder Tage dauern, brauchen Durable Execution. Ein Browser-Tab, der sich schließt, darf keinen genehmigten Refund ins Nirvana schicken.
Das Rubber-Stamp-Problem: Wenn Approval zur Farce wird
Wir wissen jetzt, wie Approval-Flows gebaut werden. Die Frage ist nicht, ob wir sie bauen können - sondern ob sie wirken. Das ehrlichste Gegenargument liegt auf der Hand: Was bringt ein Approval-Schritt, wenn der Mensch sowieso alles durchwinkt?
Die Antwort ist unbequem. Denn genau das passiert - und zwar systematisch.
Automation Complacency
Das Phänomen hat einen Namen: Automation Complacency. Je zuverlässiger ein System arbeitet, desto weniger kritisch prüft der Mensch dessen Output. Das ist kein individuelles Versagen, sondern ein gut dokumentierter kognitiver Effekt. Und er wird schlimmer, je besser die AI wird.
Die Zahlen sind eindeutig. Klinische Decision-Support-Systeme zeigen Override-Raten von 90-95 % - neun von zehn Warnungen werden weggeklickt. Ein Teil davon ist rational, weil viele Alerts klinisch irrelevant sind. Aber genau das ist das Problem: Wenn 90 % der Warnungen Rauschen sind, trainiert das System den Menschen, nicht mehr hinzuschauen. Eine JAMA-Studie mit 457 Klinikern ging weiter: Wenn die AI absichtlich fehlerhafte Empfehlungen gab, sank die diagnostische Accuracy von 73 % auf 61,7 %. Die AI machte die Entscheidungen nicht besser - sie machte die Menschen schlechter.
Wenn Rubber-Stamping zum Systemversagen wird
Der niederländische Kinderbeihilfe-Skandal von 2021 zeigt, was passiert, wenn Rubber-Stamping auf Verwaltungsebene eskaliert. Technisch war das System HITL - Sachbearbeiter mussten die ML-basierten Betrugsbewertungen prüfen und freigeben. In der Praxis hinterfragte niemand den Output. Tausende Familien wurden fälschlich als Betrüger eingestuft. Die Regierung trat zurück.
Der Europäische Gerichtshof hat 2023 im SCHUFA-Urteil (C-634/21) die juristische Konsequenz gezogen: Wenn ein Mensch den AI-Output nur durchwinkt, ohne substanziell zu prüfen, gilt das als “solely automated decision-making” unter GDPR Art. 22. Rubber-Stamping ist nicht nur ein UX-Problem - es ist ein Compliance-Risiko.
Design-Patterns gegen Rubber-Stamping
Die Forschung zeigt aber auch: Rubber-Stamping ist kein Naturgesetz. Es ist ein Design-Problem.
Cognitive Forcing Functions (Buçinca et al. 2021) zwingen den Reviewer, ein unabhängiges Urteil zu bilden, bevor die AI-Empfehlung sichtbar wird. Das klingt trivial, hat aber den stärksten Effekt auf Overreliance.
Variable Challenge Injection mischt bekannte gut/schlecht-Items in die Review-Queue - sogenannte Trap Tasks. Wer drei fingierte Fälle hintereinander falsch bewertet, bekommt Feedback. Das hält die Aufmerksamkeit hoch.
Mandatory Justification ersetzt den Approve-Button durch ein strukturiertes Begründungsfeld. Nicht “Approve/Reject”, sondern “Was genau hast du geprüft, und warum ist das Ergebnis korrekt?”
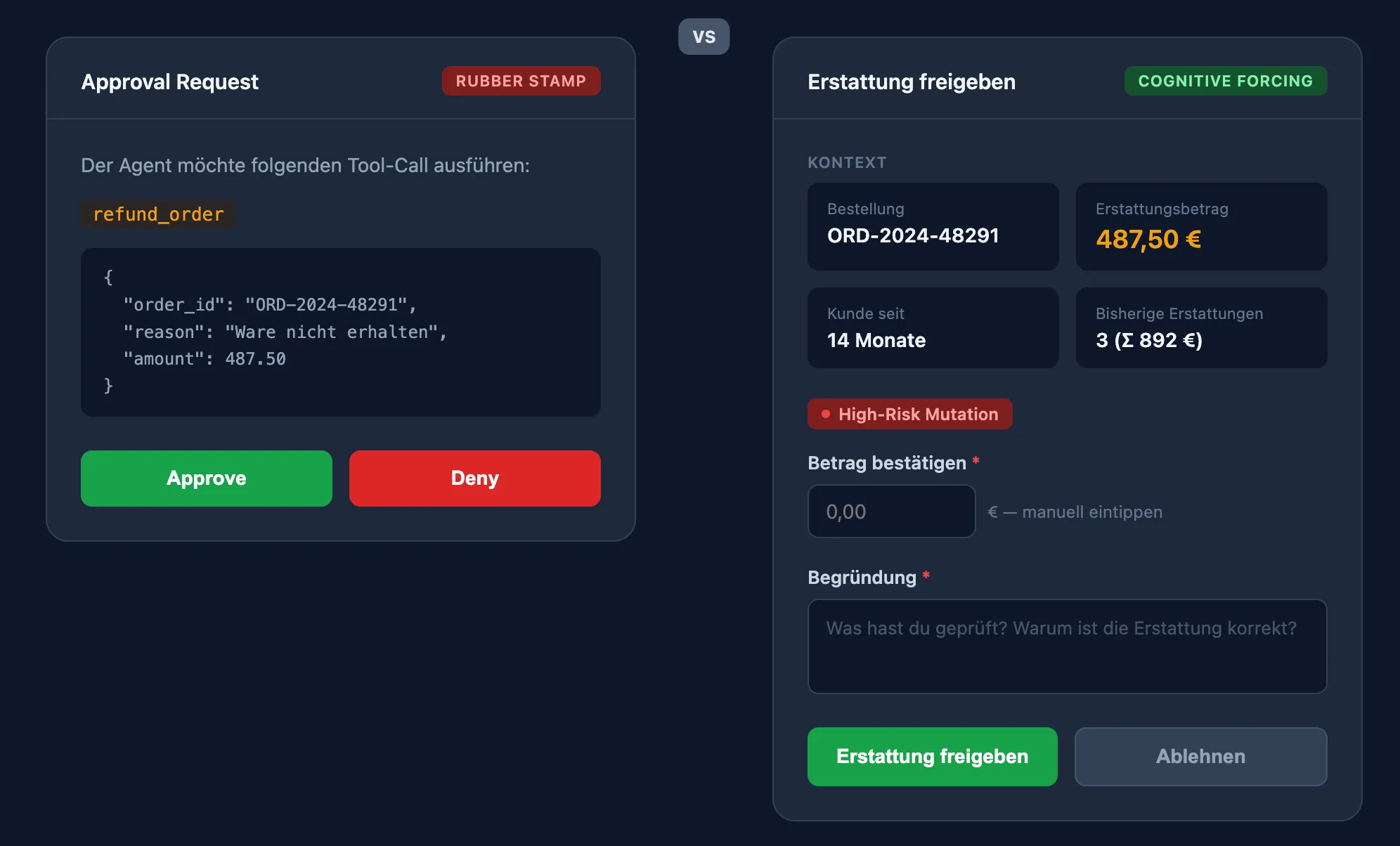
Ein Systematic Review von 2025 (Springer) destilliert das Kernfinding: AI-Erklärungen allein - also Transparenz darüber, warum die AI so entschieden hat - reichen nicht aus. Der effektivste Hebel ist aktives User Engagement. Der Mensch muss arbeiten, nicht nur zuschauen.
Und hier wird es unbequem: Buçinca et al. fanden, dass genau die Designs, die Overreliance am stärksten reduzierten, die schlechtesten subjektiven Bewertungen von Usern bekamen. Die Nutzer mochten die Cognitive Forcing Functions nicht. Gutes Approval-Design ist unbequem - by design. Wer den Approval-Prozess so gestaltet, dass er sich gut anfühlt, hat wahrscheinlich das Problem nicht gelöst.
Wer HITL als UX-Bug betrachtet, hat nie einen produktiven Incident Report gelesen.
Kontrolle ist kein Rückschritt
Die Frage war nie “HITL ja oder nein”. Die Frage ist: Wie viel Autonomie verträgt welche Aktion - und wie verändert sich das über die Zeit?
Das Risiko-Stufenmodell bestimmt, welches Tool welches Gate braucht. Aber es gibt eine zweite Achse: Wie viel Oversight braucht das Gesamtsystem? Ein neues Tool in einer unerprobten Domain startet im Audit-Modus - der Mensch reviewed jede Aktion. Mit gemessener Performance (Accuracy, Override-Frequenz, Exception Rates) kann das System graduell in den Assist-Modus wechseln: Die AI agiert, der Mensch monitort. Und irgendwann operiert es innerhalb klar definierter Grenzen nahezu autonom - aber die Grenzen bleiben architektonisch erzwungen, nicht auf Vertrauen gebaut.
Jakob Nielsen hat 2026 eine unbequeme Beobachtung gemacht: AI-Output zu verifizieren ist kognitiv oft schwieriger, als ihn selbst zu produzieren. Aber genau diese Verifikation ist die Rolle, die dem Menschen bleibt. Und sie wird umso wichtiger, je besser die Systeme werden.
Die Infrastruktur für kontrollierte Autonomie ist da. Die SDKs liefern die Primitives. Die Frage ist nur noch, ob wir sie nutzen.
Ein Agent, der nicht weiß, wann er pausieren muss, ist kein autonomer Agent - er ist ein unkontrollierter Prozess.