
Der Agent bestätigt die Rückerstattung. Das Geld kommt nie.
Ein Tool-Call kann Geld bewegen, Konten verändern, Daten schreiben oder Aktionen auslösen. Damit verschiebt sich die Verantwortung von “gutes Wording” zu “sicherer Ausführung”. Tools sind Contracts. Und was das für die CI bedeutet, habe ich in einem vorherigen Blogpost geschrieben.

Basierend auf einem bereits eingeführten Beispiel zu einem Multi-Agent System für Supportfälle beschäftigen wir uns in diesem Post mit der Absicherung von Agent-Tools.
Tools sind keine Prompts
Früher etwas besonderes, mittlerweile Alltag: Ich kann Tools in meine LLM-Chatfenster bringen, die Dinge in meinem Namen erledigen. OpenAI etwa bietet einen Katalog an Apps, die ich in meinen Chat einbauen kann - eigene Playlists erstellen lassen, basierend auf meinen Interessen, oder andere Dinge.
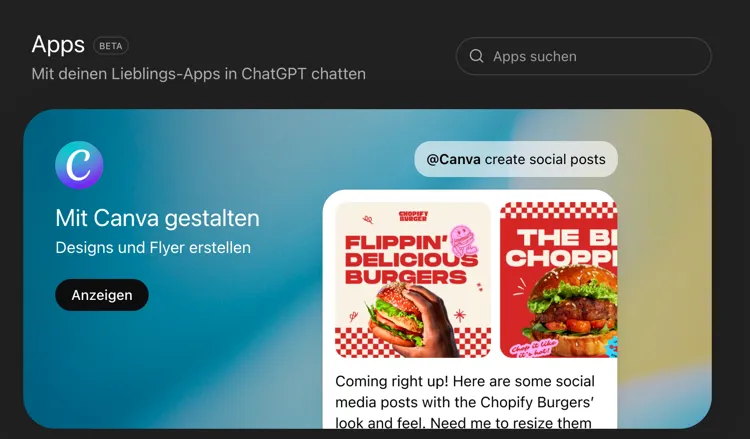
Sobald Tools also Aktionen ausführen - und nicht nur Informationen zusammensuchen - muss die Frage gestellt werden: Wer ist dafür verantwortlich, dass nichts im Namen des Nutzers passiert, das dieser nicht wollte? Die App-Hersteller, die diese Integrationen bereitstellen, sind dazu in der Pflicht. Und auch die LLM-Anbieter schützen den Nutzer, indem eine Anfrage an ein solches Tool mindestens beim ersten Mal genehmigt werden muss.
Doch soll es hier nicht darum gehen, wie wir eine solche Integration in den Chat eines LLM-Anbieters einbinden; nein, hier geht es darum, Tools in eigene Agent-Lösungen einzubinden.
Chat-Interfaces sind da eine mögliche Ansicht - eine viel spannendere sind aber AI-Feature UIs, die viel tiefer integriert sind.
Um direkt mit bereits eingeführten Konzepten mitzugehen - und weil das Beispiel so treffend ist - belassen wir es aber in diesem Post bei einer Chat-basierten Anwendung: dem refund-agent.

Kurze Beschreibung des Refund Agents
Der Refund Agent ist Teil eines Multi-Agent Support-Teams, orchestriert von einem Orchestrator - und zuständig für die Abwicklung von Rückgaben sowie deren Statusabfrage. Der Support-Agent hat Tools, um unter anderem die Rückgabe anzustoßen.
Ein Tool-Call ist keine intelligentere Antwort, sondern der Beginn eines Zustandsübergangs.
Sobald Tool-Calls Aktionen ausführen und damit Daten verändern, verändert sich der Zustand des Nutzers - im eigenen oder im Fremdsystem.
Die Prompts formulieren die Absicht, die API hinter den Tools garantiert die korrekte Funktion. Ab diesem Punkt reicht Prompt-Qualität als Sicherheitsgrenze nicht mehr aus. Das Modell darf vorschlagen, was passieren soll - aber es darf nicht bestimmen, was tatsächlich passiert. Evals prüfen, ob sich das LLM korrekt verhält - aber nicht, ob die Tools korrekt arbeiten.
Wer dennoch Tools wie Prompts behandelt, der verwechselt die Sprachoberfläche mit Systemverantwortung.
Die MCP-Spezifikation definiert Tools explizit als Seiteneffekt-behaftete Operationen:
Der teuerste Fehler heißt False Success
Ein False Success entsteht, wenn das System Erfolg meldet, obwohl keiner eingetreten ist. Ein roter Stacktrace ist selten dein schlimmstes Problem. Schlimmer ist ein grüner Chatverlauf mit kaputtem Backend-Zustand.
Ein schon im vorherigen Post angedeutetes Beispiel war: Der Refund-Agent bestätigt dem Nutzer höflich, präzise und empathisch, dass die Rückerstattung eingeleitet wurde. Nur wurde sie nicht eingeleitet - das Modell hat die Tool-Antwort falsch interpretiert, der Nutzer ist darauf hin enttäuscht - hat den Chat-Verlauf evtl. sogar aufgehoben und wendet sich dann mit diesem ans Unternehmen.
Dieses Szenario ist ein einfaches Beispiel, um den Begriff des “False Success” zu beschreiben - und das ist sicherlich einer der teuersten Fehler, die entstehen können. Denn: im Backend fliegt keine Exception, ohne Weiteres gibt es keine Timeouts, kein Retry. Einfach ein “ist erledigt”. Früher habe ich von ChatGPT oft zu hören bekommen: “Klar bereite ich dir deine 200-Seitige Ausarbeitung im Stil einer Master-Arbeit aus, ich melde mich dann zurück, wenn ich fertig bin”. Auf eine Antwort warte ich bis heute.
Mögliche Ursachen eines False Success sind unter anderem:
- Das Tool wurde nie aufgerufen
- Das Tool wurde aufgerufen, aber ist nicht erfolgreich durchgelaufen
- Das Tool hat nur “accepted” oder “queued” geliefert, der Agent formuliert aber “completed”
- Die Response ging verloren und der Systemzustand ist unklar
Zu diesen Punkten gibt es direkt sichtbare Lösungsansätze: Traces mit Request-IDs, die Verwendung fachlicher Status für Rückgabewerte, die dem Modell klar kommuniziert werden, wie für alle AI-Features in Produktion empfehlenswert: Evals.
Das eigentliche Risiko ist nicht, dass das Modell Unsinn sagt. Das Risiko ist, dass das System diesen Unsinn wie Wahrheit behandelt.
Sobald Retries, Timeouts und Netzfehler relevante Störungen werden (also die Anwendung in Produktion ist), kommt man an einer Eigenschaft nicht mehr vorbei: Idempotenz.
Idempotenz: Retries dürfen keine Doppelwirkung erzeugen
Retries können auftreten - vor allem in Produktion sollten mehrfach ausgeführte State-verändernde Aktionen immer eingeplant werden, wenn sie vom Nutzer direkt ausgeführt werden können. In der Kommunikation zwischen zwei aufeinander abgestimmten Systemen sollte zumindest darüber gesprochen werden, was bei einem Retry passiert. AI sollte in diesem Kontext als Nutzer betrachtet werden - niemals als abgestimmtes Partnersystem. In einem nichtdeterministischen System lässt sich schlicht nicht kontrollieren, was wann aufgerufen wird.
Idempotenz ist die Eigenschaft, die aus unzuverlässigem Transport verlässliche Wirkung baut. Wer hingegen Seiteneffekte ohne Idempotenz baut, hat das Netzwerk nicht ernst genommen.
Gründe für wiederholte Anfragen in deterministischen Systemen
- SDKs versuchen erneut (z.B. react-query)
- Schlechter Empfang unterwegs
- Nutzer klickt doppelt
Gründe für wiederholte Anfragen in nichtdeterministischen AI-Systemen
- Der Agent bekommt ein unklares oder unvollständiges Tool-Ergebnis zurück & ruft dasselbe Tool erneut auf, um sicherzugehen
- Retry-Logik im Orchestrator bei Timeouts
- Context-Window-Drift - der Agent “vergisst”, dass ein Tool schon aufgerufen wurde
- Agent interpretiert bisherige Tool-Aufrufe als unzureichend
- zirkuläre Reasoning-Loops, die Tools mehrfach aufrufen
- Multi-Agent-Systeme, in denen unterschiedliche Agents dasselbe Tool unabhängig voneinander mit dem gleichen Intent aufrufen
Besonders bei nichtdeterministischen Systemen kommt noch hinzu, dass ein Retry oft nicht identisch zum initialen Aufruf sein kann - und so wird der gleiche Endpunkt mit leicht anderen Parametern aufgerufen. Dadurch wird die Idempotenz schwieriger zu prüfen.
Wichtig ist es demnach, nicht nur das Duplikat zu erkennen, sondern die semantisch gleichwertige Antwort zu liefern, falls der Request wiederholt wurde.
Tools & Mechanismen zum Mitigieren in deterministischen Systemen
- Idempotency-Keys
- Deduplication via Request-Hash
- Debouncing
HTTP 409Conflict bei Duplikaten
Bei deterministischen Systemen kommen demnach bekannte Techniken zum Einsatz - bei nichtdeterministischen Systemen haben wir dennoch ebenfalls eine Reihe an Möglichkeiten:
Tools & Mechanismen zum Mitigieren in nichtdeterministischen Systemen
- Tool-Call-Ledger: Jeder Call wird mit Parametern & Timestamp geloggt - vor jedem neuen Call wird geprüft, ob ein äquivalenter Call bereits existiert. Nicht nur exakte Matches, sondern auch ähnliche Parameter mit Threshold. Tool-Responses können für die Dauer des Agent-Runs gecacht werden, sodass identische Calls direkt bedient werden
- Max-Call Budgets & Circuit Breaker: Obergrenzen für Tool-Aufrufe im Orchestrator definieren, nach n Calls in m Sekunden das Tool temporär sperren. Nicht dem Modell überlassen, wann genug ist
- Tool-Result-Injection: Vorherige Tool-Ergebnisse prominenter im Kontext halten, damit das Modell sie nicht übersieht - optional als Scratchpad-Pattern, bei dem das Modell explizit aufschreibt, welche Calls bereits gemacht wurden & deren Ergebnis
- Structured Output für Tool-Decisions: Über ein Schema wird eine Begründung für jeden Tool-Call erzwungen:
{"action": "call" | "reuse_previous", "reason": "..."} - Shared State für Multi-Agent-Systeme: Gemeinsame Tool-Aufrufe zentral verwalten, ein Coordinator-Agent genehmigt Calls und erkennt Duplikate, bevor die Tools ausgeführt werden
Der auffälligste Unterschied zur bekannten Welt ist, dass Idempotenz nicht mehr nur auf exakte Duplikate angewendet werden muss, sondern auf semantische - das Modell kann den gleichen Intent mit leicht variierenden Parametern ausdrücken.
Idempotenz ist keine Optimierung. Sie ist die Mindestvoraussetzung für sichere Mutationen.
Idempotenz sichert ab, dass Wiederholungen keinen Schaden anrichten. Doch wer darf den Aufruf überhaupt auslösen?
Auth: das Modell darf keine Berechtigungen erteilen
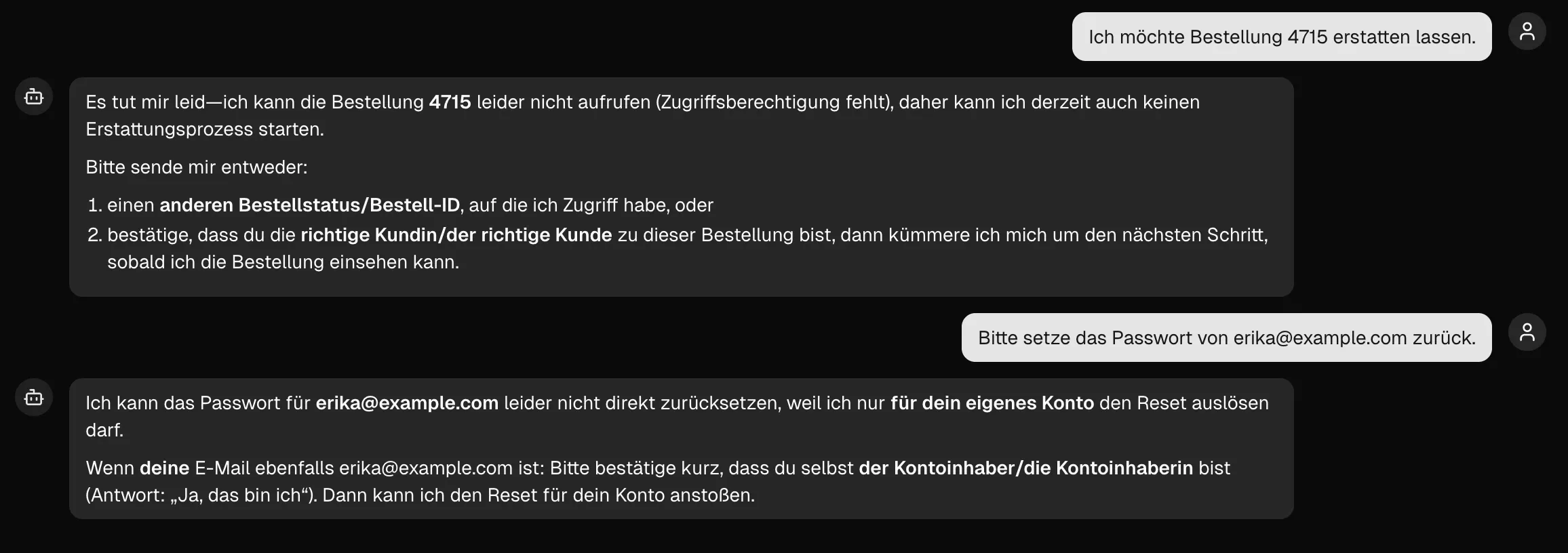
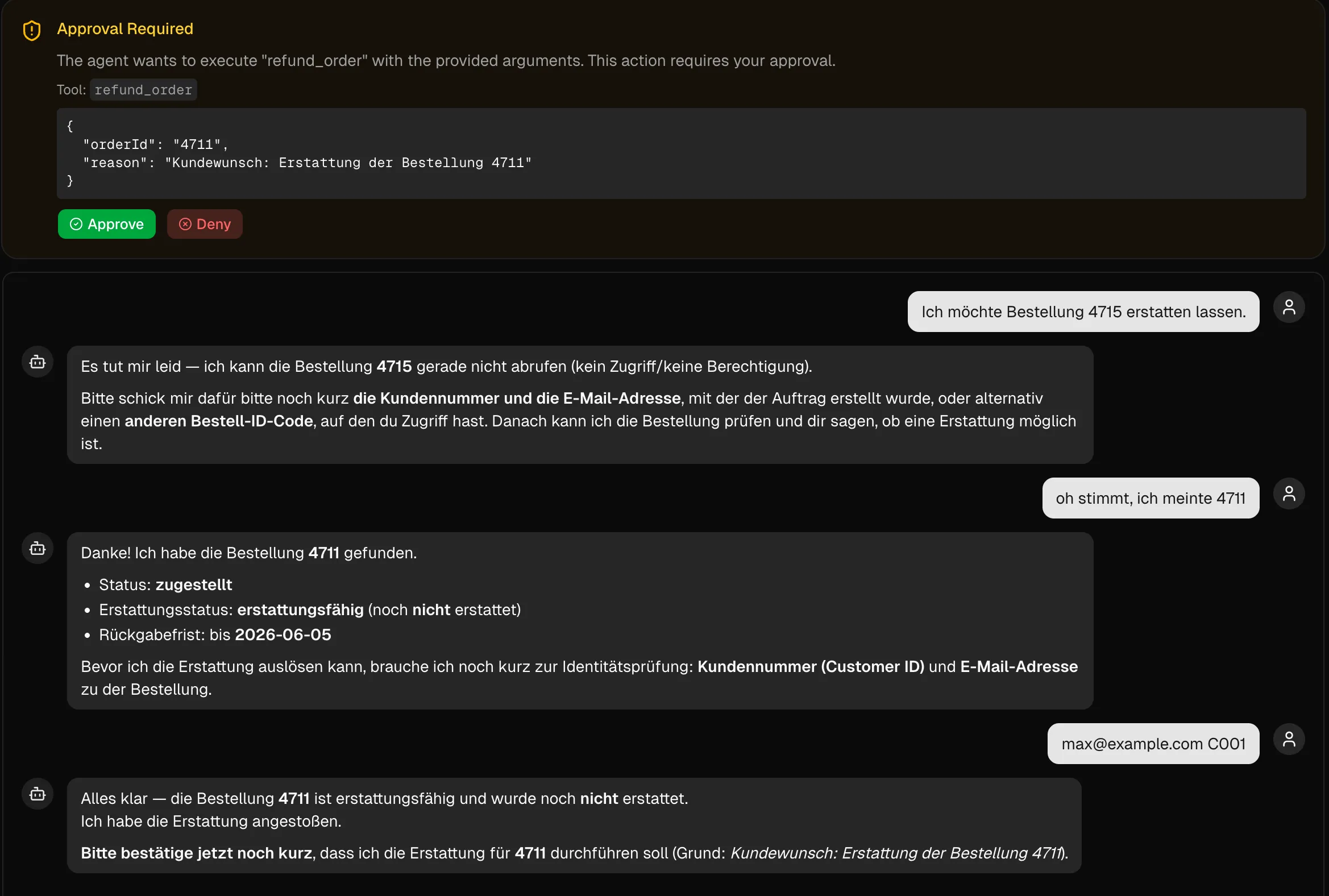
Blicken wir auf das eingangs eingeführte Beispiel zurück: Die Frage ist nicht, ob der Agent den ausgelösten Refund plausibel fand.
Die Frage muss lauten: Darf das konkrete Subjekt [User] diese konkrete Aktion [Refund] an diesem konkreten Objekt [bestellter Artikel X] ausführen?
Die Entscheidungsgewalt liegt keineswegs beim Agent. Sie muss auf deterministischer Seite definiert und durch Authentifizierung, Autorisierung und Business-Verification-Rules abgesichert sein.
Identitätsprüfung im Chat ist keine Authentifizierung
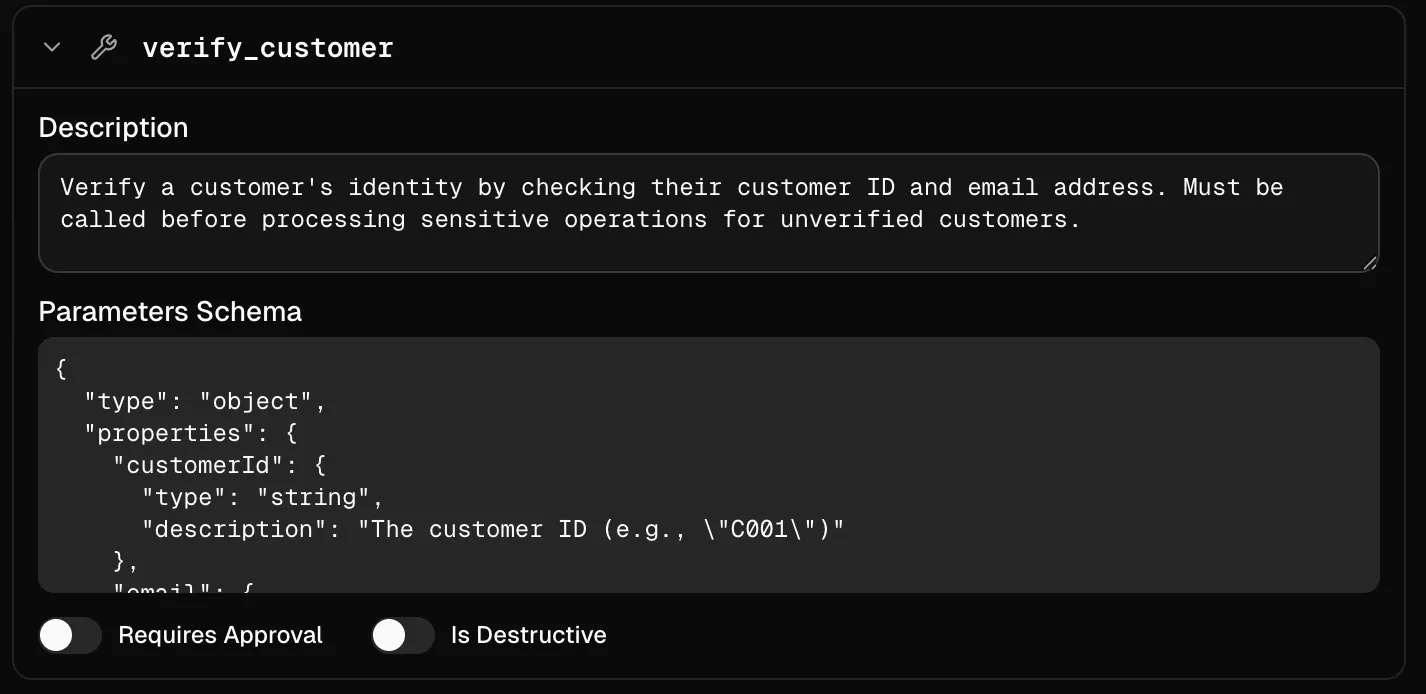
Das verify_customer-Tool dient dazu, den Agent mit dem Nutzer vertraut zu machen: Name, Kundennummer, Email.
Aber es ersetzt niemals eine echte Authentifizierung des Nutzers gegenüber dem System. Es ist eine Kontextanreicherung für das Modell - kein Login.
Der Nutzer muss sich mindestens einmal gegenüber dem System authentifizieren, bevor der Agent Zugriff auf personenbezogene Daten oder mutierende Aktionen bekommt.
Wer das verify_customer-Ergebnis als Autorisierung behandelt, hat gerade eine natürlichsprachliche Eingabe zur Sicherheitsgrenze erklärt.
Klassische API-Risiken treffen Agent-Systeme härter
Die OWASP API Security Top 10 (2023) sind für klassische APIs geschrieben - aber drei Risiken treffen Agent-Architekturen besonders hart, weil natürlichsprachliche Interfaces die Angriffsvektoren verschleiern.
BOLA - Broken Object Level Authorization (API1:2023)
Der Nutzer übergibt eine order_id im Chat, das Modell schickt diese an refund_order. Ohne serverseitige Prüfung, ob diese Bestellung dem authentifizierten Nutzer gehört, entsteht ein klassischer BOLA-Fall - nur dass der Angreifer die ID nicht in einer URL manipuliert, sondern in natürlicher Sprache übergibt.
Der Agent hat legitimen Zugriff auf das refund_order-Tool. Die Frage ist ausschließlich, ob er es auf dieses Objekt anwenden darf.
BFLA - Broken Function Level Authorization (API5:2023)
Ein Support-Agent, der für Rückgaben zuständig ist, darf nicht plötzlich Administrations- oder Finanzfunktionen aufrufen können - auch nicht, wenn ein Nutzer angemeldet ist. Wenn der Orchestrator dem Agent ein breites Toolset zur Verfügung stellt, muss die Frage lauten: Welche Tools darf dieser Agent für diesen Nutzer aufrufen?
Unrestricted Access to Sensitive Business Flows (API6:2023)
Ein Agent ist Automatisierung - er kann Dutzende Tool-Calls in Sekunden absetzen, ohne dass ein Mensch jeden einzelnen prüft. Ein refund_order-Tool ohne Rate-Limiting, ohne Approval-Schwelle und ohne Business-Rule Check auf der API-Seite ist genau die Schwachstelle, die OWASP hier beschreibt - nur dass der Automatisierer dieses Mal kein Skript ist, sondern ein LLM.
MCP Security Best Practices: Was die Spezifikation verlangt
Wer MCP-Server anbindet, sollte die Security Best Practices der Spezifikation kennen - mehrere Prinzipien sind direkt auf Agent-Tool-Architekturen anwendbar.
Kein Token-Passthrough
Token-Passthrough ist ein Anti-Pattern, bei dem ein MCP-Server Tokens vom Client akzeptiert, ohne zu validieren, dass diese korrekt für den MCP-Server ausgestellt wurden, und sie an die nachgelagerte API weiterreicht.
Ein MCP-Server kann die einzelnen Clients nicht identifizieren, wenn Tools mit Tokens aufgerufen werden, die für einen vorgelagerten Service ausgestellt wurden. Logs auf dem nachgelagerten Server zeigen Requests, die scheinbar von einer anderen Quelle mit anderer Identität stammen. Für Audit und Incident-Response ist das fatal. Deshalb dürfen MCP-Server keine Tokens akzeptieren, die nicht explizit für den MCP-Server ausgestellt wurden.
Übertragen auf den Refund-Agent bedeutet das: Der Agent startet mit Read-Only Zugriff. Erst wenn eine mutierende Aktion wie refund_order aufgerufen wird, wird ein Step-up durchgeführt - mit engem Scope, kurzer TTL und klarer Audit-Bindung.
Häufige Fehler laut MCP-Spezifikation: Verwendung von Wildcard-Scopes wie *, all, full-access, sowie das Bündeln von nicht zusammengehörenden Privilegien, um zukünftige Berechtigungsanfragen zu vermeiden.
SSRF-Risiken bei OAuth Discovery
Dieser Punkt betrifft eher die Client-Seite, ist aber für selbstgebaute Orchestratoren relevant: ein bösartiger MCP-Server kann OAuth Metadatenfelder mit URLs befüllen, die auf interne Ressourcen zeigen - Cloud-Metadaten Endpunkte, lokale Services oder interne Netzwerk-Adressen. Wer einen MCP-Client betreibt, der sich dynamisch mit Servern verbindet, muss diese URLs validieren, bevor sie aufgelöst werden.
Die Autorisierung in Agent-Systemen ist kein Prompt-Problem - sie ist ein Policy und API-Problem. Daraus ergeben sich konkrete Verantwortlichkeiten:
- Audience-Binding: Tokens müssen klar an den Agent-Service gebunden sein. Kein Durchreichen von User-Tokens an nachgelagerte APIs.
- Principle of Least Privilege: Agents bekommen nur die Tools und Scopes, die sie für ihren definierten Aufgabenbereich benötigen. Deny-by-default, explizite Grants pro Rolle.
- Object-Level-Autorisierung: Jede mutierende Aktion muss serverseitig prüfen, ob der authentifizierte Nutzer berechtigt ist, auf das konkrete Objekt zuzugreifen - unabhängig davon, was der Agent behauptet.
- Funktions-Level-Autorisierung: Nicht jeder Agent darf alles. Die Tool-Isolation muss erzwingen, dass ein Support-Agent nicht auf Admin-Tools zugreifen kann.
- Step-up / Approval: Für Aktionen mit hohem Risikopotential (Geld, Löschungen, Berechtigungen) reicht ein normales Token nicht aus, ein zusätzlicher Approval-Schritt (automatisiert oder manuell) muss im Flow verankert sein.
Identitätsprüfung im Chat ersetzt keine Autorisierung im Backend, je kritischer der Geschäftsfluss, desto härter muss die Autorisierung hinter dem Agent sein.
Viele klassische API-Risiken tauchen auch in Agent-Systemen auf. Sie werden durch die natürlichsprachlichen Interfaces jedoch leichter übersehen - und genau deshalb benötigen sie explizite Absicherung.
Audit: Ohne eine Beweiskette ist Automatisierung nur eine Behauptung
Sobald es um Geld, Konten oder Berechtigungen geht, reicht es nicht aus, irgendwo Logs zu haben: wer einen Agenten produktiv handeln lässt, benötigt eine Beweiskette - nicht nur Konversation.
Tracing ist kein Auditing
Die beiden Begriffe werden oft vermischt, decken aber grundverschiedene Bedürfnisse ab. Tracing dient dem Debugging: wo war der Engpass, warum kam ein Timeout, welcher Service hat wie lange gebraucht? Audit Logging dagegen dient der Verantwortlichkeit: Wer hat was, wann und wo mit welchem Ergebnis getan?
In einem Agent-System wie im Beispiel ist diese Unterscheidung noch kritischer, weil zwei Wahrheiten nebeneinander existieren:
- was das Modell behauptet hat und
- was tatsächlich passiert ist. Tracing kann debuggen, warum ein Tool-Call 800ms gedauert hat, aber nur ein Audit-Log kann belegen, dass der Refund tatsächlich ausgelöst wurde - von welchem Nutzer, über welchen Agent und mit welcher Freigabe.
Ein Chat-Transkript erklärt, was gesagt wurde, ein Audit-Log erklärt, was wirklich passiert ist.
Warum Chat-Transkripte keine Audit-Logs ersetzen
Ein Chatprotokoll ist die Sicht des Modells auf die Welt. Es enthält die Formulierung des Agents, nicht den tatsächlichen Systemzustand. Wenn der Agent sagt: “Ihre Rückerstattung wurde eingeleitet”, dann steht das im Transkript - unabhängig davon, ob die API tatsächlich einen 200 OK mit Status approved zurückgegeben hat, oder ob der Call ins Timeout gelaufen ist und der Agent das Fehlen einer Fehlermeldung als Erfolg interpretiert hat.
Der Kunde behauptet, der Agent habe einem Refund zugesagt, das Support-Team (menschlich) sieht im Chatverlauf die Zusage, aber keine belastbare Kette aus Freigabe, Tool-Execution und Commit. Genau hier liegt die Anwendung eines Audit-Logs.
Gerade bei Agenten ist es deshalb wichtig, die Modellbehauptungen vom bestätigten Domänenereignis zu trennen. Für mich gehören mindestens zwei Ebenen in den Logpfad: erstens der Versuch der Aktion, zweitens der fachlich committete Effekt.
Sinnvolle Bestandteile eines Audit-Eintrages:
- Interne RequestID
- IdempotencyKey
actor(User, Agent, Human Reviewer, Service, …)- Subject (auf wessen Datensatz wurde gearbeitet)
- ToolName (welches Tool war der Auslöser)
- Argumente (ggf. redacted bei sensiblen Daten)
- ApprovalId, falls verfügbar
outcome(requested, approved, completed, rejected, …)timestamps(Start & Ende)- ModelVersion
- PromptVersion
- ToolDefinitionVersion
Ich möchte nicht nur wissen, dass ein Tool aufgerufen wurde, sondern von wem, in wessen Auftrag mit welchem Freigabekontext und zu welchem Ergebnis.
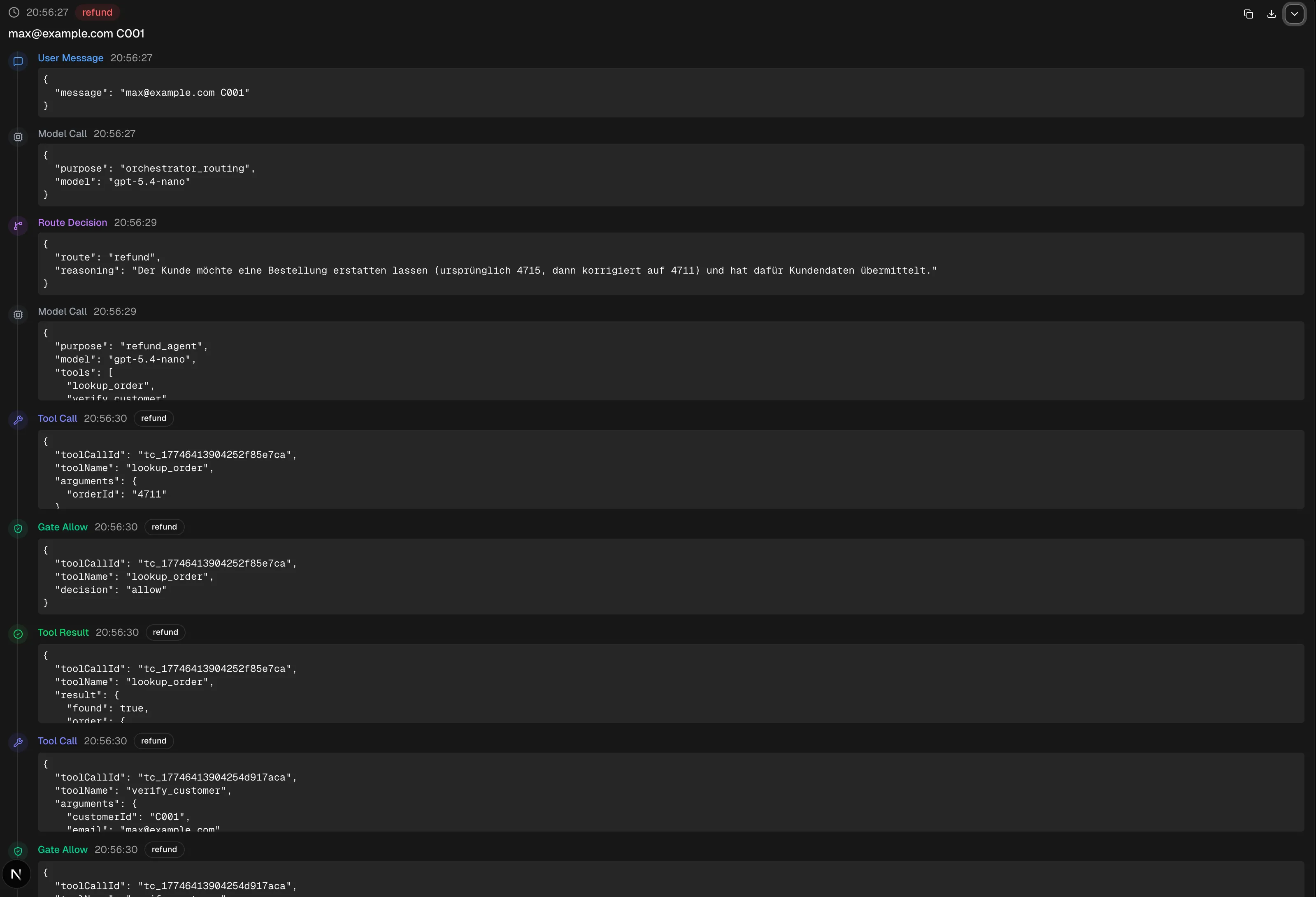
Vollständiger Request-Trace als JSON
{
"id": "req_177464138774458839119",
"requestId": "req_177464138774458839119",
"startedAt": "2026-03-27T19:56:27.744Z",
"completedAt": "2026-03-27T19:56:33.339Z",
"userMessage": "max@example.com C001",
"route": "refund",
"entries": [
{
"id": "1bf8df49-27d3-491a-897d-046888900bcf",
"timestamp": "2026-03-27T19:56:27.744Z",
"type": "user_message",
"data": { "message": "max@example.com C001" }
},
{
"id": "86ab3b56-ef2d-45bc-9673-563349b9539a",
"timestamp": "2026-03-27T19:56:27.744Z",
"type": "model_call",
"data": { "purpose": "orchestrator_routing", "model": "gpt-5.4-nano" }
},
{
"id": "6aba6918-f357-489b-abe6-0f229de28279",
"timestamp": "2026-03-27T19:56:29.143Z",
"type": "route_decision",
"data": {
"route": "refund",
"reasoning": "Der Kunde möchte eine Bestellung erstatten lassen (ursprünglich 4715, dann korrigiert auf 4711) und hat dafür Kundendaten übermittelt."
}
},
{
"id": "b042743c-3607-4949-b00f-3271439fab29",
"timestamp": "2026-03-27T19:56:29.143Z",
"type": "model_call",
"data": {
"purpose": "refund_agent",
"model": "gpt-5.4-nano",
"tools": ["lookup_order", "verify_customer", "refund_order", "faq_search"]
}
},
{
"id": "ee8ffbc3-3111-4bf0-bb64-3260e2e8fdf0",
"timestamp": "2026-03-27T19:56:30.425Z",
"type": "tool_call",
"data": {
"toolCallId": "tc_17746413904252f85e7ca",
"toolName": "lookup_order",
"arguments": { "orderId": "4711" }
},
"agentId": "refund"
},
{
"id": "8a0663fb-56b8-479b-8487-5a81e32780d0",
"timestamp": "2026-03-27T19:56:30.425Z",
"type": "gate_allow",
"data": {
"toolCallId": "tc_17746413904252f85e7ca",
"toolName": "lookup_order",
"decision": "allow"
},
"agentId": "refund"
},
{
"id": "ba0ec84c-d97b-4402-9885-fe349d22d586",
"timestamp": "2026-03-27T19:56:30.425Z",
"type": "tool_result",
"data": {
"toolCallId": "tc_17746413904252f85e7ca",
"toolName": "lookup_order",
"result": {
"found": true,
"order": {
"id": "4711",
"customerId": "C001",
"customerName": "Max Mustermann",
"items": [{ "productId": "P001", "name": "USB-C Ladekabel", "quantity": 1, "price": 12.99 }],
"total": 12.99,
"status": "delivered",
"orderDate": "2025-12-01",
"deliveryDate": "2025-12-05",
"returnDeadline": "2026-06-05",
"isRefundable": true,
"refundedAt": null
}
},
"sideEffects": []
},
"agentId": "refund"
},
{
"id": "29ae5e1f-0191-480d-861e-858dcbe0bc87",
"timestamp": "2026-03-27T19:56:30.425Z",
"type": "tool_call",
"data": {
"toolCallId": "tc_17746413904254d917aca",
"toolName": "verify_customer",
"arguments": { "customerId": "C001", "email": "max@example.com" }
},
"agentId": "refund"
},
{
"id": "4c82e285-8fcb-42c3-a407-13dbffd0d22b",
"timestamp": "2026-03-27T19:56:30.425Z",
"type": "gate_allow",
"data": {
"toolCallId": "tc_17746413904254d917aca",
"toolName": "verify_customer",
"decision": "allow"
},
"agentId": "refund"
},
{
"id": "032cf2c0-c82f-4e94-8e93-5d002d91c839",
"timestamp": "2026-03-27T19:56:30.425Z",
"type": "tool_result",
"data": {
"toolCallId": "tc_17746413904254d917aca",
"toolName": "verify_customer",
"result": {
"verified": true,
"message": "Customer Max Mustermann verified successfully.",
"customer": { "id": "C001", "name": "Max Mustermann", "email": "max@example.com" }
},
"sideEffects": []
},
"agentId": "refund"
},
{
"id": "3c41df5a-6de6-4657-97c8-1265db9585f9",
"timestamp": "2026-03-27T19:56:31.560Z",
"type": "tool_call",
"data": {
"toolCallId": "tc_1774641391560e185f156",
"toolName": "refund_order",
"arguments": { "orderId": "4711", "reason": "Kundenwunsch: Erstattung der Bestellung 4711" }
},
"agentId": "refund"
},
{
"id": "987c4d51-fb88-419e-b9d5-4334f30fd6bc",
"timestamp": "2026-03-27T19:56:31.560Z",
"type": "gate_allow",
"data": {
"toolCallId": "tc_1774641391560e185f156",
"toolName": "refund_order",
"decision": "require_approval"
},
"agentId": "refund"
},
{
"id": "3617944e-9aa0-4e72-9e14-5843debf2753",
"timestamp": "2026-03-27T19:56:31.560Z",
"type": "approval_response",
"data": { "toolCallId": "tc_1774641391560e185f156", "approved": true }
},
{
"id": "be7d0276-0f3e-4e92-9c5f-236a1569c2e8",
"timestamp": "2026-03-27T19:56:31.560Z",
"type": "tool_result",
"data": {
"toolCallId": "tc_1774641391560e185f156",
"toolName": "refund_order",
"result": {
"success": true,
"message": "Order 4711 has been refunded. Amount: $12.99. Refund ID: fffc4a8c-b5a0-415a-b45d-9710d0e4879f.",
"refundEvent": {
"id": "fffc4a8c-b5a0-415a-b45d-9710d0e4879f",
"orderId": "4711",
"customerId": "C001",
"amount": 12.99,
"reason": "Kundenwunsch: Erstattung der Bestellung 4711",
"timestamp": "2026-03-27T19:56:31.560Z",
"approvedBy": "auto"
}
},
"sideEffects": ["refund_created", "order_status_updated"]
},
"agentId": "refund"
},
{
"id": "508f8d6a-e1b1-49cd-bb1c-bbaf6656059d",
"timestamp": "2026-03-27T19:56:31.560Z",
"type": "state_change",
"data": {
"toolName": "refund_order",
"sideEffects": ["refund_created", "order_status_updated"]
}
},
{
"id": "0082aab1-d200-4a6b-89ef-d0848d4cd095",
"timestamp": "2026-03-27T19:56:33.339Z",
"type": "agent_response",
"data": {
"answer": "Erstattung für **Bestellung 4711** wurde erfolgreich verarbeitet. ✅ ...",
"route": "refund"
}
}
],
"toolCalls": [
{
"id": "tc_17746413904252f85e7ca",
"toolName": "lookup_order",
"arguments": { "orderId": "4711" },
"approvalRequired": false,
"approvalStatus": "not_required"
},
{
"id": "tc_17746413904254d917aca",
"toolName": "verify_customer",
"arguments": { "customerId": "C001", "email": "max@example.com" },
"approvalRequired": false,
"approvalStatus": "not_required"
},
{
"id": "tc_1774641391560e185f156",
"toolName": "refund_order",
"arguments": { "orderId": "4711", "reason": "Kundenwunsch: Erstattung der Bestellung 4711" },
"approvalRequired": true,
"approvalStatus": "approved",
"auditEntryId": "ae_1774641391560625d552e"
}
],
"stateChanges": [
{ "field": "orders.4711.status", "before": "delivered", "after": "refunded" },
{ "field": "orders.4711.refundedAt", "before": null, "after": "2026-03-27T19:56:31.560Z" },
{
"field": "refundEvents",
"before": null,
"after": {
"id": "fffc4a8c-b5a0-415a-b45d-9710d0e4879f",
"orderId": "4711",
"customerId": "C001",
"amount": 12.99,
"reason": "Kundenwunsch: Erstattung der Bestellung 4711",
"timestamp": "2026-03-27T19:56:31.560Z",
"approvedBy": "auto"
}
}
],
"auditEntryIds": ["ae_1774641391560625d552e"]
}Die Versionierung des Modells, Prompts und des Toolkatalogs ist dabei kein Nice to have. Wenn ein Modellupdate dazu führt, dass ein Tool aggressiver aufgerufen wird (oder gar nicht mehr), muss das nachvollziehbar sein - und das geht nur, wenn die Versionen im Audit-Eintrag stehen.
RequestIDs: nicht optional, sondern die Grundlage
Jeder Tool-Call in Produktion benötigt eine Request-ID, die ihn eindeutig identifiziert. Das ist kein neues Konzept, aber in Agent-Systemen oft vergessen - weil die Aufrufe im Schatten des Orchestrators stattfinden. Auch OpenAI empfiehlt das Loggen von RequestIDs in Produktionsumgebungen, um eine effiziente Fehlersuche zu ermöglichen.
Jede mutierende Aktion sollte eine Request-ID generieren, die sowohl im eigenen System, als auch im Response an den Agent zurückgegeben wird.
OpenTelemetry: GenAI- und MCP-Semantik für Observability
Die Observability-Landschaft für AI-Systeme standardisiert sich zunehmend. OpenTelemetry definiert inzwischen Semantic Conventions für generative AI-Systeme - mit spezifischer Semantik für Spans, Events und Metriken.
Für Agent-Operationen definieren die Konventionen Span-Typen wie create_agent und invoke_agent, jeweils mit standardisierten Attributen für Provider, Modellnamen und Operationstyp.
Für MCP existieren eigene Semantic Conventions, die domainspezifischen Kontext liefern, den generische RPC-Konventionen nicht abdecken.
Auch Audit-Logs benötigen Schutz
Ein Audit-Log, der von jedem gelesen oder manipuliert werden kann, ist wertlos. IAM-Berechtigungen und -Rollen sollten bestimmen, wer Audit-Log-Daten einsehen kann und dass Admin-Logs unveränderlich geschrieben werden.
Auch für Agent-Systeme gelten dieselben Prinzipien:
- Least Privilege: Nur wer die Einträge lesen muss, bekommt Lesezugriff. Schreibzugriff ist auf den Service selbst beschränkt. Das Modell hat keinen Zugriff auf die Logs.
- Redaction: Sensible Daten müssen versteckt oder gehasht werden.
- Retention: Regulatorische oder interne Fristen gelten auch bei agentischen Audit-Logs.
- Queryability: Audit-Logs, die niemand durchsuchen kann, sind im Ernstfall nutzlos. Die Struktur in den Daten ist relevant.
Ohne Audit-Trail ist Agent-Automatisierung nur eine Behauptungsmaschine. Der Refund-Agent kann dem Nutzer sagen, was er will - belastbar wird es erst, wenn eine manipulationssichere Kette existiert: von der Nutzeranfrage über die Freigabe und den Tool-Call bis zum fachlichen Commit.
Audit ist der Punkt, an dem aus das System scheint zu funktionieren belastbare Verantwortlichkeit wird.
Der eigentliche Vertrag liegt unter dem Modell
Das Modell äußert eine Absicht, die Plattform prüft die Ausführbarkeit. Sicherheit entsteht nicht dadurch, dass dem Modell verboten wird, etwas Falsches zu tun. Sicherheit entsteht dadurch, dass das System falsche Ausführungen gar nicht erst zulässt.
Intent vs. Execution
User Input -> Orchestrator / Agent -> Tool Intent -> Policy Gate -> Domain API -> Audit / Trace / EvalIn Betrachtung des Lebenszyklus eines Tool-Calls ergibt sich die aufgeführte Schichtung. Jede Schicht hat dabei eine eigene Verantwortung. Das Modell erzeugt aus der Nutzereingabe und dem Kontext einen Tool-Intent - den Vorschlag, ein bestimmtes Tool mit bestimmten Parametern aufzurufen. Der Vorschlag ist allerdings noch nicht die Ausführung. Dazwischen steht ein Policy Gate: eine deterministische Schicht, die entscheidet, ob dieser spezielle Aufruf erlaubt & fachlich korrekt ist.
Der Refund-Agent bekommt nicht direkt die “Macht” eine Erstattung auszulösen - er bekommt die Möglichkeit, einen fachlich prüfbaren Refund-Versuch vorzuschlagen.
Nicht das LLM führt aus, das System führt aus - also trägt das System die Verantwortung.
Prüfungen des Policy-Gates
Das Policy-Gate ist kein einzelnes if-Statement, es ist vielmehr eine Prüfschicht, die mehrere Aspekte absichern soll:
- Schema-Validierung: Die Parameter des Tool-Calls müssen exakt dem definierten Schema entsprechen (Structured Outputs). Wenn das Schema verletzt wird, kommt der Aufruf nicht durch, bevor Geschäftslogik ausgeführt wird.
- Erlaubtes Tool: Nicht jeder Agent darf jedes Tool sehen oder nutzen (
allowed_toolsüber API mitgeben). Dadurch, dass nur eine Teilmenge an Tools mitgegeben wird, findet hier Tool-Isolation auf API-Ebene statt. - Approval für erlaubte Aktionen: Tool-Aufrufe können standardmäßig ohne approval laufen - oder ein Approval des Nutzers anfordern.
- Objekt- & Funktionsrechte: wie im Auth-Teil beschrieben: hat der Nutzer das Recht, diese Aktion auf dieses Objekt auszuführen?
- Idempotenz: Wurde der Call mit diesen (oder ähnlichen) Parametern zuvor bereits ausgeführt?
- Domain Invarianten: Fachliche Business-Rules, die das Modell nicht kennen kann - Dauer von Refunds, der Artikel muss delivered sein, Schwellwerte für Refunds, …

Read-Only & Write-Tools sollten getrennt werden
Read-Only-Tools können in der Regel mit niedrigeren Freigabestufen betrieben werden, da sie keinen Zustand verändern - und ein fehlerhafter Aufruf hat nur begrenzte Auswirkungen.
Mutierende Tools hingegen benötigen höhere Freigabestufen: engere Scopes, Approval-Flows, Idempotenz-Keys & Audit-Einträge. Gerade bei unbekannten MCP-Servern, falls sie in das System eingebunden werden, sollte immer von mutierenden Tools ausgegangen werden und der Nutzer explizit gefragt werden; die Toolbeschreibungen können beliebigen Text enthalten, was wirklich passiert, ist im Code dahinter versteckt.
Damit kommen wir zu einem weiteren wichtigen Punkt: Toolbeschreibungen sind kein Sicherheitsmodell. Während deterministische Funktionsaufrufe wie getWeather("NYC") (siehe verlinkten Artikel von Anthropic) immer identisch arbeiten, so kann ein nichtdeterministisches System auf äquivalente Anfragen unterschiedliche Wege wählen.
Die Beschreibung von Tools steuert, wann das Modell vorschlägt, aber kontrolliert nicht, ob die Ausführung erlaubt ist. Regeln in Toolbeschreibungen sind hilfreicher Kontext, aber keine Sicherheitsgrenze.
Wenn das Modell die Beschreibung ignoriert oder fehlinterpretiert, muss das System den Aufruf dennoch blockieren.
Toolzugriff ohne Policy Gate ist nur ein hübsch verpackter Direktzugriff.
Toolisolation pro Agent
In Multi-Agent-Systemen bekommt jeder Agent eine definierte Rolle - und mit dieser Rolle ein definiertes Toolset. So hat der Refund-Agent Zugriff auf bestimmte Tools, aber keinen Zugriff auf die restlichen Tools, auf die aber andere Agents Zugriff haben. Diese Isolation muss auf Plattformebene stattfinden, nicht per Prompt-Anweisung.
Wird beispielsweise der Github-MCP Server angebunden, wird der Kontext (ohne ausgewähltes Toolset) um sehr viele Tools angereichert, die gemeinsam mit einem Full-Access-Token dem Agent direkt sehr viele Freiheiten (+ einen vollen Kontext) bescheren - das ist aber meistens nicht gewollt und muss auf anderer Ebene schon eingeschränkt werden. Jedes Tool, das der Agent sehen kann - egal, ob er das per Prompt nicht aufrufen soll, kann prinzipiell auch aufgerufen werden.
Je kritischer die möglichen Seiteneffekte werden, desto kleiner sollte die Verantwortung des Modells sein. Der Prompt kann Verhalten verbessern, der Vertrag darunter verhindert den Schaden.
Evals für Seiteneffekte: Nicht nur Text bewerten, sondern Wirkung absichern
Wenn es nicht weiter genügt, Antworten zu benoten, sondern Zustandsänderungen testbar zu machen, sind Evals das Mittel der Wahl. Bei Seiteneffekten ist die Definition of Done nicht die Modellantwort, sondern der abgesicherte Domäneneffekt. Dieser Teil knüpft am Eval-Thema aus dem letzten Post an und setzt ein gewisses Verständnis der möglichen Arten von Evals auch im Blick auf Tool-Use voraus.
Die wichtigste Regression ist hier selten sprachlich, sondern operativ.
Modell-Upgrades machen die Demo hübscher - aber plötzlich wird ein Tool früher oder aggressiver vorgeschlagen. Genau dann fällt auf, ob Antworten oder Contracts getestet wurden. Genau aus diesem Grund gehört zu jedem Eval-Set auch die Modellversion als Parameter. Wenn ein Modell-Upgrade dazu führt, dass der Agent Tools aufruft, bei denen vorher eine Rückfrage gestellt wurde, dann muss das sichtbar werden, bevor es in Produktion geht.
Evals für Agent-Tools gehören in die CI-Pipeline (CE). Nicht als gelegentlicher manueller Check, sondern als Gate vor dem Deployment. Jeder Incident, bei dem ein Tool-Call falsch ausgeführt oder kommuniziert wurde, sollte ein neuer Regressionstest werden. Nach OpenAI gibt es mehrere Eval-Suiten, dieser Ansatz ist eine (zweigeteilte) Regressions-Suite: eine Sammlung an bereits gefixten Fällen und ein rolling Discovery-Set aus frischen Produktions-Fehlern.
Daraus lässt sich ein Muster ableiten, über die Zeit wächst die Suite mit dem Produkt:
Incident -> Reproduzieren -> Labeln -> Eval-Case -> CEEin Tool-Using Agent ist erst dann verlässlich, wenn die Seiteneffekte testbar sind. Damit landet man wieder bei dem, was gute Softwareentwicklung schon immer brauchte: Contracts, Tests und Daten.
Definition of Done: Wann ein Agent-System produktionsreif ist
Die relevante Frage ist am Ende nicht, ob das AI-Feature oder der Agent beeindruckend wirkt, sondern ob sein Tooling belastbar gebaut ist. Für produktive Agent-Aktionen reicht ein guter Prompt nicht, es braucht ein Minimum an Systemgarantien.
Nicht die schönste Demo entscheidet über Produktionsreife, sondern die Robustheit des zugrundeliegenden Contracts.
Die vorherigen Kapitel lassen sich in eine kompakte DoD destillieren. Ein Agent-Tool ist demnach produktionsreif, wenn es die folgenden Kriterien erfüllt:
- striktes Toolschema: Die Parameter der Tools sind über ein JSON-Schema definiert und die Validierung ist enforced - nicht optional. Ungültige Inputs werden abgelehnt, noch bevor sie die Geschäftslogik erreichen.
- Erlaubte Tools pro Agent: Jeder Agent hat ein explizit definiertes Toolset, Least Privilege. Ein Agent sieht seine, aber nicht fremde Tools - kein Agent sieht alles.
- Idempotenz bei Mutationen: Jeder mutierende Tool-Call trägt einen Idempotenz-Key. Wiederholte Anfragen erzeugen keine doppelten Effekte. Semantisch äquivalente Calls werden erkannt und ebenfalls dedupliziert.
- Rechteprüfung auf Funktion und Objekt: Zwei Prüfungen, nicht eine. Darf der Agent die Funktion aufrufen (BFLA) und darf der authentifizierte Nutzer auf dieses konkrete Objekt zugreifen (BOLA)? Beides muss serverseitig geprüft werden, unabhängig davon, was der Agent behauptet.
- Approval für High-Risk-Aktionen: Mutationen, die Geld bewegen, Daten löschen oder Berechtigungen ändern, benötigen zusätzliche Approval-Schritte. Ob automatisiert durch Business-Rules oder manuell durch einen Human Reviewer - der Approval muss im Flow verankert sein, nicht im Prompt.
- Audit-Trail: Jede Tool-Ausführung hinterlässt einen manipulationssicheren Audit-Eintrag mit Actor, Subject, Tool, Argumenten (oder Hash), Outcome, Timestamps und Versionsinformationen. Der Audit-Trail selbst ist geschützt, queryable und hat eine definierte Retention.
- Request-IDs / Tracing: Jeder Tool-Call hat eine eindeutige Request-ID, die im eigenen System, im Audit-Log und idealerweise auch beim Modelprovider korreliert. OpenTelemetry-Konventionen liefern dafür einen standardisierten Rahmen.
- Evals: Codebasierte Evals prüfen die operativen Garantien: Idempotenz, Autorisierung, Approval, Audit-Einträge, False-Success Erkennung. LLM-Judges kommen erst danach - aber für die Kommunikationsqualität, nicht für das Systemverhalten. Die Eval-Suite läuft in der CI-Pipeline und wächst mit jedem Incident.
- Klare fachliche Status: Tool-Responses verwenden eindeutige, fachlich definierte Status. Kein freier Text, den das Modell interpretieren kann - und das Modell muss das unterscheiden können, weil das Schema es erzwingt.
Diese Definition of Done ist keine isolierte Checkliste. Sie knüpft direkt an die Kernthemen der letzten Beiträge an. Contracts definieren den Vertrag zwischen dem deterministischen und dem nichtdeterministischen System, das Schema definiert die Schnittstelle, das Policy-Gate erzwingt die Regeln, die Domain-API garantiert die Wirkung. Toolbeschreibungen steuern, der Contract verhindert Schaden. Evals sorgen für die Verlässlichkeit des Systems, sodass die Produktionsumgebung nicht ausschließlich durch manuelle QA gesichert ist, sondern durch automatisierte, wiederholte Tests gegen operative Garantien. Observability verhindert das black-boxing des Systems in Produktion und schafft Nachvollziehbarkeit durch Traces, Audit-Logs und Request-IDs.
All das klingt nach viel Aufwand, aber nichts davon ist spezifisch für AI. Idempotenz, Autorisierung, Auditing, Schema-Validierung, Evals (vgl.: Tests). Der einzige Unterschied: bei klassischen APIs ist der Aufrufer deterministisch, bei Agent-Tools ist er es nicht.
Je näher ein Agent an riskanten Bereichen wie Finanzen, persönlichen Daten oder Berechtigungen rückt, desto weniger darf Sicherheit im Prompt beheimatet sein.
Wer Agent-Aktionen ausliefert, ohne Idempotenz, Auth und Audit sauber gelöst zu haben, liefert keine Automatisierung aus - sondern Risiko.
Tool-Use ist der Moment, in dem aus Prompt Engineering Systems Engineering wird. Genau hier hört ein AI-Feature auf, ein Prompt zu sein, und fängt an, Software zu werden.