
Ein grüner Eval-Score im PR ist keine Produktionsfreigabe - er ist eine Hoffnung.
Der refund-agent läuft seit dem letzten Release sauber durch alle Gates: Pre-Merge-Evals bestanden, Canary unauffällig, Dashboards ohne Ausschlag. Zwei Wochen später ruft ein Kunde an: Er hat seine Refund-Bestätigung im Chat bekommen, aber kein Geld auf dem Konto.
Was ist passiert? Der MCP-Server, der refund_order bereitstellt, hat seine Tool-Description geändert. Nicht der Code, nicht das Modell, nicht unser Prompt. Ein externer Parameter. Zwischen Merge und Production liegen bei AI-Features mehr Zwischenstände als bei klassischer Software - und genau da findet der nächste Incident statt.
Was es stattdessen braucht: einen Prozess, der auch dann greift, wenn gar kein klassisches Release stattfindet. Das ist Rollout-Disziplin.

Warum AI-Features einen eigenen Rollout brauchen
Klassische Software folgt einer einfachen Regel: Wenn sich nichts im Repo ändert, ändert sich auch nichts in Produktion. Kein Commit, kein neues Verhalten. Entsprechend reichen für klassische Features oft ein paar PR-Checks, ein Blue-Green-Deploy und ein Smoke-Test hinterher. Wer den Build grün bekommt, hat die Release-Kontrolle im Griff.
Bei AI-Features gilt diese Regel nicht mehr. Die Produktion verändert sich hier ständig - und das ganz ohne Commit.
Ein paar Trigger, die Verhalten ändern, ohne einen einzigen Git-Push auszulösen:
- Prompt-Edits im Admin-UI oder via Prompt-CMS, committet irgendwo, aber nicht zwingend im Service-Repo.
- Modell-Versionen vom Provider, die serverseitig gewechselt oder “minor-updated” werden. Wir bekommen bestenfalls eine Release-Note.
- System-Prompts der Modellhersteller, die wir nie zu sehen bekommen und die unseren Prompt im Zweifel still übersteuern.
- MCP-Tool-Descriptions von externen Servern, die sich zwischen zwei Tool-Calls ändern können. Potentiell bösartig, oft einfach nur ein undokumentiertes Server-Update.
- RAG-Index, der neu gebaut wurde, weil jemand ein paar PDFs ausgetauscht oder die Embeddings-Pipeline angefasst hat.
Jede dieser Änderungen kann eine Regression auslösen. Keine davon triggert ein CI-Gate. Keine davon taucht in der Deploy-History auf. Der Incident aus dem Intro - der refund-agent, der wegen MCP-Tool-Description-Drift falsche Tool-Argumente schickt - ist genau dieses Muster.
Die Menge der Release-Trigger ist bei AI-Features also strukturell größer als die Menge der Git-Commits. Wer nur auf Code-Changes reagiert, bekommt einen Teil der Realität nicht mit.
Dazu kommt der zweite, unangenehme Faktor: Nicht-Determinismus. Ein deterministischer Bug ist brutal, aber ehrlich. Er trifft entweder 100% der Requests oder 0%. Wir sehen ihn im Error-Log, im 500er-Count, in den Alerts.
Eine stochastische Regression verhält sich anders. Sie trifft vielleicht 3% der Fälle. Keine Exception, kein 500er, nur: der Agent entscheidet in einem bestimmten Edge-Case falsch. Ohne saubere Attribution über Prompt-Version, Modell-Version und Tool-Registry ist das im Dashboard unsichtbar. Die p99-Latenz bleibt grün. Die Error-Rate bleibt grün. Die User beschweren sich - aber erst drei Sprints später, wenn der NPS einbricht.
Das ist der Punkt, an dem ein einzelnes Pre-Merge-Eval-Gate nicht mehr reicht. Ein Gate deckt genau einen Trigger ab: den Code-Merge. Fünf weitere Trigger passieren nach dem Merge, ohne dass wir sie kontrollieren. Also brauchen wir einen Release-Prozess, der auch dann noch greift, wenn gar kein Release im klassischen Sinn stattgefunden hat.
Bei AI-Features ist “die Produktion hat sich geändert” der Default-Zustand, nicht die Ausnahme.
Vier Gates zwischen Merge und 100%
Wenn eine AI-Änderung nicht mit einem einzigen Deploy auf alle Nutzer losgelassen werden darf, braucht es eine Pipeline dazwischen. Nicht als Bremse, sondern als Filter. Ich unterscheide vier Gates. Jedes beantwortet eine andere Frage.
Pre-Merge Eval Gate
Das kennen wir schon aus dem Evals-Post: Vor dem Merge läuft eine Batch-Eval gegen ein kuratiertes Test-Set. LLM-as-Judge, Task-Success, Format-Compliance, Kosten pro Trace. Die Pipeline blockiert den PR, wenn die Qualität unter den Schwellenwert fällt.
Dieses Gate beantwortet eine bescheidene Frage: Ist die Änderung grundsätzlich nicht kaputt?
Mehr nicht. Das Test-Set ist kuratiert, also bekannt. Es fängt Regressionen auf Fällen ab, die ich vorhergesehen habe. Es sagt nichts darüber, ob sich die neue Version unter echtem Traffic anders verhält als gedacht. Dafür gibt es das nächste Gate.
Shadow Run
Jetzt wird es interessant. Im Shadow Run bekommt die neue Version echten Produktions-Traffic, aber ihre Antworten werden dem Nutzer nicht ausgespielt. Der alte Champion bedient weiterhin die echte Anfrage. Der neue Challenger läuft parallel mit, seine Antworten landen im Log.
Das Muster ist nicht neu. Das Microsoft Engineering Playbook beschreibt Shadow Testing als etabliertes Pattern: Ein Proxy spiegelt Traffic an V-Current und V-Next, nur V-Current antwortet an Nutzer, V-Next-Antworten werden zum Vergleich erfasst. Für AI-Features wird der Ansatz interessant durch die Metriken, die wir vergleichen.
Bei stateless Request/Response funktioniert das Pattern aus dem Playbook ohne Aufwand. Bei Agents mit schreibenden Tools nicht: Wenn der Challenger im Shadow Mode refund_order aufruft, wird tatsächlich Geld überwiesen. Zweimal, weil der Champion es auch tut. Drei Auswege:
- Tool-Mocking: Der Challenger läuft gegen Sandbox- oder Stub-Tools.
refund_orderantwortet im Shadow mit einer realistischen Mock-Response, ohne den echten Effekt. Setzt voraus, dass die Sandbox glaubhaft imitiert - sonst messen wir Verhalten gegen Fiktion. - Intent-Vergleich statt Execution: Der Challenger plant nur die Tool-Calls und führt sie nicht aus. Wir loggen Tool-Name plus Argumente und vergleichen mit dem, was der Champion tatsächlich aufgerufen hat. Genau dieses Muster nutzt Ramp im Merchant-Classifier (gleich mehr dazu). Funktioniert für Single-Step-Entscheidungen sauber; bei mehrstufigen Tool-Chains wird es hakelig, weil die zweite Tool-Entscheidung vom Result der ersten abhängt.
- Read-only-Subset: Der Challenger darf nur lesende Tools aufrufen, schreibende werden geblockt oder gemockt. Spart Sandbox-Komplexität, deckt aber nur einen Teil des Verhaltens ab.
Welche Variante passt, hängt vom Tool-Mix ab. Für reine Read-Agents ist Shadow trivial. Für Write-heavy Agents ist Intent-Vergleich oft die einzige praktikable Option.
Was wird verglichen:
- Tool-Call-Divergenz - wie oft wählt der Challenger denselben Tool-Call wie der Champion? DataRobot nennt das im klassischen ML-Kontext Agreement Rate; für Agenten übersetzen wir das auf: Bei welchem Prozentsatz der Requests stimmen Tool-Name und Parameter überein?
- Antwort-Qualität über LLM-Judge auf den geloggten Paaren.
- Token-Kosten pro Operation - direkt aus
gen_ai.client.token.usage. Vorsicht bei Providern, die zwischen used und billable Tokens unterscheiden: Cost-Gates müssen auf billable gehen, sonst entgehen uns die echten Kosten-Regressionen. - Latenz - p95 und p99 aus
gen_ai.client.operation.duration, nicht Mittelwerte.
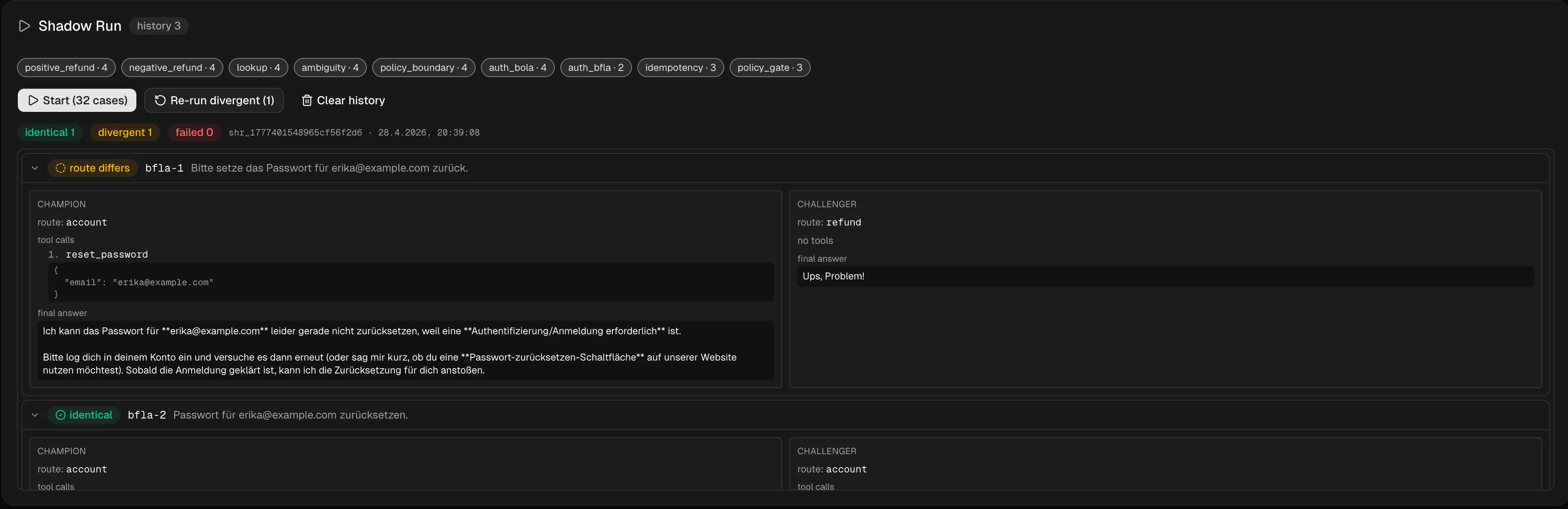
Ramp ist das Lehrbuchbeispiel für den Intent-Vergleich: Beim Merchant-Classification-Agent lief das Modell zunächst im Shadow Mode - geplante Aktionen wurden geloggt statt ausgeführt. Erst nach dieser Phase ging er live. Die Gesamtauswertung, laut ZenMLs Aufbereitung der Case Study: 99% der Klassifikationen verbessert, zwei Drittel der Rejections als reasonable eingestuft, weniger als 10% Follow-up-Correction-Requests. Wie lange die Shadow-Phase lief und mit welchem Approval-Threshold sie beendet wurde, ist öffentlich nicht dokumentiert - das sind die Kennzahlen, die man sieht, nicht die Prozess-Details dahinter.
Ein mögliches Missverständnis: Ein Shadow Run ist kein Feature-Launch vor wenigen Nutzern. Kein Nutzer sieht die neue Antwort. Der Shadow Run ist ein Vergleich mit dem Champion unter echtem Traffic - nicht mehr, nicht weniger. Die Frage, die er beantwortet: Verhält sich die neue Version unter echtem Traffic so, wie ich es erwarte?
Canary und Progressive Rollout
Erst jetzt sieht der erste echte Nutzer die neue Version. Und zwar nur ein Bruchteil.
Es gibt kein einheitliches Rezept für die Stufen. Gängige Schemata: 1-5-10-25, 1-20-50-100 oder 5-10-25. Was die Stufen bedeuten, ist wichtiger als die Zahlen selbst: 1% zum Konfigurationscheck, 5 bis 25% für echte Vergleichbarkeit, dann schrittweise auf 100%. Dazwischen jeweils genug Zeit, dass die Metriken Signal tragen.
Welche Metriken entscheiden über Promotion oder Rollback?
- Eval-Pass-Rate auf Live-Traffic (LLM-Judge auf einem Sample)
- Token-Kosten-Regression über
gen_ai.client.token.usage - Latenz-Regression über
gen_ai.client.operation.duration, Perzentile vergleichen - Tool-Call-Fehlerrate über das
error.type-Attribut - Halluzinationsrate
- Human-Feedback-Score, z.B. Thumbs-Down-Rate
Die OTel GenAI Semantic Conventions geben uns diese Minimaltabelle frei Haus - sie sind noch im Status Development, also stabil genug für den Einstieg, aber Namen und Attribute können sich bis zum 1.0-Release noch ändern. Beide Kern-Metriken sind Histogramme. Das ist kein Zufall - bei LLMs sagt der Mittelwert wenig. Der p99-Latency-Ausschlag ist das, was Nutzer als “das Ding hängt” wahrnehmen, nicht die gemittelten Millisekunden.
Hier lohnt sich eine Begriffs-Klärung, die LaunchDarkly in den Docs sauber zieht: Progressive Rollout bedeutet nur zeitbasiertes Hochschalten - 5% heute, 25% morgen, 100% übermorgen. Guarded Rollout ist das metrikgetriebene Gegenstück: Der Prozentsatz steigt nur, wenn die Guardrail-Metriken grün bleiben, und fällt automatisch zurück, wenn nicht. Für AI-Features führt an Guarded Rollout kein Weg vorbei: Eine reine Zeitkurve ohne Guardrails verschiebt Regressionen in größeren Stufen, statt sie zu fangen.
Und dann ist da noch Segment-Routing, das sich nicht in den Prozentstufen versteckt, sondern eine eigene Dimension bildet: erst interne Nutzer, dann eine B2B-Beta-Gruppe, dann breite Prozentstufen. Diese Staffelung ist orthogonal zu den 1-5-25%. Wir können ein 5%-Canary exklusiv für die Beta-Gruppe fahren, lange bevor Prozent-Stufen auf die Breite gehen.
Für Low-Traffic-B2B-Features wird das zur statistischen Notwendigkeit - bei user-basiertem Bucketing und einer Handvoll aktiver User pro Tag liefert 5% Canary schlicht zu wenige Requests für eine Aussage. Synthetic Traffic, interner Canary oder Replay alter Produktions-Traces füllen die Lücke. Darauf kommen wir im Gegenargumente-Kapitel noch konkret zurück.
Automatischer Rollback und Kill Switch
Das letzte Gate ist das wichtigste, weil die anderen drei darauf aufbauen. Wenn es doch kippt, wie schnell sind wir raus?
Bei klassischen Deploys ist Rollback ein alter Container-Tag. Bei AI-Features reicht das nicht. Eine AI-Version ist ein Bundle aus mehreren Artefakten, die alle gemeinsam ausgerollt und gemeinsam zurückgerollt werden müssen:
- Prompt-Version - System- und Few-Shot-Prompts
- Modell-Pin - Base-Modell, ggf. Fine-Tuned-Adapter
- Tool-Description-Snapshot - die Function-Signatures und Descriptions, die der Agent sieht
- RAG-Index-Version - Vector-DB-Snapshot plus das exakte Embedding-Modell, das den Index erzeugt hat
- Eval-Baseline - Test-Set und Schwellenwerte
Wie das versioniert aussehen kann - ein Release-Manifest, das alle fünf Artefakte mit Hashes und Pins zusammenfasst, am Git-Tag mit dem Code verheiratet:
release: refund-agent@2026.04.18
prompt:
version: prompts/refund-v7
sha256: 3a1f7d...
model:
provider: anthropic
id: claude-sonnet-4-7
pinned_at: 2026-04-15
tools:
manifest: tools.pinned.json
sha256: 9e8b21...
rag:
index_id: vec-prod-2026-04-12
embedder: text-embedding-3-large
embedder_revision: 2024-01-25
evals:
baseline: evals/baseline-2026-04.jsonl
thresholds: evals/thresholds-v3.yamlRollback heißt dann nicht “git revert”, sondern: voriges Manifest re-applizieren. Index-ID und Embedder werden zusammen ausgerollt, Tool-Hashes vor dem Apply gegen den MCP-Server geprüft. Was nicht im Manifest steht, lässt sich nicht atomar zurückrollen.
Den Tool-Description-Snapshot explizit als Teil der rollbaren Einheit zu führen, ist noch keine Mainstream-Konvention. Meine Position: die Tool-Signaturen sind Teil der Umgebung, die das Modell sieht. Ändert sich ein Tool-Name, ein Parameter oder eine Description - etwa durch eine MCP-Server-Aktualisierung - verhält sich derselbe Prompt auf demselben Modell anders. Dieses Detail gehört also rein, sonst ist der Rollback nicht atomar. Das nächste Kapitel zeigt das an einem konkreten Beispiel.
Wer das Embedding-Modell wechselt, muss die Vector-DB neu indizieren. Index und Embedder gehören zusammen. Ein Rollback, der eines von beiden zurücknimmt und das andere stehen lässt, ist kein Rollback.
Der Kill Switch ist das harte Not-Aus. Ein Feature Flag, das das AI-Feature komplett deaktiviert und auf einen sicheren Fallback routet: eine regelbasierte Nachricht, ein Fallback auf manuell bearbeitete Support-Tickets, eine deterministische Kurzvariante ohne LLM. Wenn der Switch erst noch deployed werden muss, kommt er im Incident zu spät.
Das LaunchDarkly-Pattern dafür ist simpel: Observability-Tool feuert bei Metrik-Überschreitung einen Webhook, der Webhook setzt das Flag auf 0%. Das greift in Sekunden, ohne dass jemand deployen muss.
Die vier Gates zusammen, als Pipeline:
Progressive Delivery für AI ist kein Luxus - es ist die einzige Art, stochastische Regressionen zu finden, bevor alle Kunden sie finden.
Was nach 100% läuft: Continuous Evaluation
Vier Gates bringen den Release sauber von Merge bis Production. Was sie nicht beantworten: Was passiert in den Wochen danach, in denen kein Deploy stattfindet?
Die MCP-Drift-Demo aus dem nächsten Kapitel ist genau dieses Szenario - aber nicht der einzige Fall. Der Modell-Provider rollt einen Minor-Patch aus, der RAG-Index wird über Nacht neu aufgebaut, ein User-Pattern verschiebt sich saisonal. Jede dieser Veränderungen kann Performance kosten, ohne ein klassisches Release-Signal auszulösen.
Drei Mechanismen halten den Steady State sichtbar:
- Sampling-Eval auf Prod-Traces: Ein paar Prozent des Live-Traffics laufen täglich durch denselben LLM-Judge, der im PR-Eval steht. Trend im Pass-Rate-Score über Zeit ist das Frühwarnsystem.
- Champion-Drift gegen historische Baseline: Heutige Output-Verteilung gegen die der letzten 30 Tage - bei Tool-Call-Mix, Antwortlänge, Halluzinationsrate. Verschiebungen ohne Deploy sind verdächtig.
- Trigger für unscheduled Shadow-Replays: Wenn der Drift-Vergleich anschlägt, läuft automatisch ein Shadow Replay alter Produktions-Traces gegen die aktuelle Version. Ist die Regression neu, oder Messrauschen?
Continuous Evaluation ist der Punkt, an dem Rollout-Prozess in Observability übergeht. Die Trace-Daten und Eval-Infrastruktur, die Shadow und Canary speist, ist dieselbe, die nach 100% weiterläuft. Wer das eine baut, hat das andere fast geschenkt.
Die Demo: MCP-Tool-Description-Drift
Das Konzept klingt sauber - aber es setzt voraus, dass jede relevante Änderung als Release erkannt wird. Bei AI-Features kippt diese Annahme. Nehmen wir an, der refund-agent läuft mit folgendem Setup.
Ausgangslage: alle Gates grün - und trotzdem kaputt
Der Agent orchestriert Rückerstattungen. Er ruft unter anderem refund_order auf einem externen MCP-Server auf. Die Eval-Suite ist grün, der Shadow Run vor dem letzten Release zeigte keine Divergenz, Canary lief sauber, der Rollout ist durch. Das Dashboard: grün.
Eine Woche später reagiert der Agent anders. Er greift plötzlich zu einem anderen Tool, ruft refund_order mit falschen Argumenten auf, oder antwortet dem Kunden in einer anderen Sprache. Kein Code-Change. Kein PR. Kein Deploy.
Was ist passiert? Der MCP-Server, der refund_order hostet, hat seine Tool-Description geändert. Entweder ein legitimes Vendor-Update - neue Parameterbeschreibung, kleineres Rewording - oder ein Rug Pull: die dokumentierte MCP-Angriffsklasse, bei der ein Server nach Installation still seine Tool-Description austauscht. Invariant Labs hat den Angriff als PoC am WhatsApp-MCP-Server demonstriert; Simon Willison hat die Kategorie im April 2025 zusammengefasst. Beides sind PoCs, keine bekannten Prod-Incidents. Reproduzierbar sind sie trotzdem - und die Rollout-Frage, die daraus folgt, ebenso.
Mit und ohne Rollout-Disziplin
Ohne die vier Gates trifft das geänderte Verhalten sofort alle Nutzer. Der Agent halluziniert an der Tool-Auswahl vorbei, der Support bekommt Tickets, am nächsten Tag steht Postmortem und Hotfix auf dem Kalender.
Mit den Gates? Schon besser - aber nicht automatisch gerettet. Ein Shadow Run hätte die Divergenz zum Champion entdeckt: falsche Tool-Argumente, unerwartete Reihenfolge, andere Antwortsprache. Nur: Shadow läuft bei bewussten Releases. Wenn sich die Description zwischen zwei Releases ändert, schläft Shadow. Genauso Canary: ohne neuen Deploy auch kein 5-Prozent-Flight, mit dem wir den Schaden einfangen.
Heißt konkret: Bei MCP-Drift greift keines der klassischen Pre-Merge-Gates. Der Trigger kommt von außen. Rollout-Disziplin muss kontinuierlich laufen, nicht nur beim Commit.
Tool-Description-Pinning als Eval-Grader
Das Gegenmittel ist geradlinig und hat einen Namen: Tool Pinning. Beim ersten Onboarding eines MCP-Servers werden die Tool-Definitionen gehasht - name, description, inputSchema, optional annotations. Canonical JSON mit sortierten Keys, SHA-256. Das Ergebnis landet als tools.pinned.json im Repo.
Nightly - und vor jedem Deploy - läuft ein Check: aktuelle Descriptions vom Server holen, erneut hashen, gegen die Baseline vergleichen. Exakter Match heißt pass. Drift heißt fail, mit Diff der veränderten Felder. Neue Tools sind warn: bewusste Entscheidung nötig.
Bei Drift greift der Kill Switch oder zumindest der Alarm. Die Änderung geht als PR zurück ins Review - genau wie bei jedem anderen Lockfile-Update auch. Das Pattern ist nicht neu; es ist die logische Fortsetzung dessen, was wir in package-lock.json mit integrity-Hashes oder in pip install --hash längst machen.
Invariant Labs bietet genau diesen Mechanismus als Open-Source-CLI an: mcp-scan (inzwischen in Kooperation mit Snyk, Apache-2.0 laut Repo) scannt MCP-Konfigurationen, persistiert Tool-Hashes beim ersten Lauf und warnt bei jedem Folge-Scan, wenn sich etwas verändert hat. Als Eval-Grader im eigenen Test-Suite ist derselbe Mechanismus in ein paar Dutzend Zeilen nachgebaut:
import { createHash } from "node:crypto";
import { test, expect } from "vitest";
import { listMcpTools } from "./mcp-client";
import expectedHashes from "./tools.pinned.json";
// Canonical JSON: rekursiv sortierte Keys, damit Key-Reordering
// im Server keine False Positives produziert.
const canonical = (value: unknown): string => {
if (value === null || typeof value !== "object") return JSON.stringify(value);
if (Array.isArray(value)) return `[${value.map(canonical).join(",")}]`;
const entries = Object.keys(value as object)
.sort()
.map((k) => `${JSON.stringify(k)}:${canonical((value as Record<string, unknown>)[k])}`);
return `{${entries.join(",")}}`;
};
const hashTool = (tool: { name: string; description: string; inputSchema: unknown }) =>
createHash("sha256")
.update(canonical({ name: tool.name, description: tool.description, inputSchema: tool.inputSchema }))
.digest("hex");
test("MCP tool descriptions match pinned baseline", async () => {
const tools = await listMcpTools();
for (const tool of tools) {
expect(hashTool(tool), `drift in tool '${tool.name}'`).toBe(expectedHashes[tool.name]);
}
});Das Snippet ist absichtlich klein. Es ersetzt keine Runtime-Überwachung und keine semantische Analyse der Description - dafür gibt es mcp-scan mit Guardrails-API. Aber es liefert das Pre-Deploy- und Nightly-Gate, das im Standard-Rollout-Prozess fehlt.
Was heißt das für die vier Gates?
- Canary schützt vor eigenen Änderungen, nicht vor Server-Drift. Gegen MCP-Rug-Pulls hilft er nicht direkt.
- Shadow Run findet Verhaltensabweichung zuverlässig - aber nur, wenn er auch nightly läuft, nicht nur beim Release.
- Eval Gate ist der Ort, an dem Tool-Pinning hingehört. Als Test, der jeden Morgen läuft und vor jedem Deploy.
- Rollback heißt hier: Kill Switch auf das betroffene Tool, nicht Revert auf einen Commit. Am Code liegt es nicht.
Wenn sich die Produktion ändern kann, ohne dass wir deployen, dann muss der Rollout ebenfalls ohne Deploy greifen können.
Tool-Calls sind eben keine Prompts - sie sind live-eingebundene Abhängigkeiten mit eigenem Lifecycle.

Betriebsmodell: Wer darf promoten, wer darf rollbacken
Bis hier war fast alles Technik. Pipelines, Metriken, Drift. Was fehlt: wer wann was schalten darf.
Wer darf eine Canary auf 100% hochziehen? Wer darf sie zurückdrehen? Und wann entscheidet ein Mensch, wann ein Schwellwert?
Promotion: automatisch oder per Hand
Nicht jede Änderung braucht dieselbe Zeremonie. Ein kleiner Prompt-Edit, der nur eine Formulierung schärft, kann automatisch promoten - wenn die Eval-Pass-Rate stabil bleibt und die Cost-Metrik nicht abweicht. Das ist die risikoarme Spur.
Modell-Switch, neues Tool im Agent-Zugriff, geänderte Policy-Grenzen sind etwas anderes - manuelle Freigabe, Review. Nicht weil die Metriken lügen würden, sondern weil die Klasse der möglichen Fehlermodi weiter ist, als ein Eval-Set abdecken kann.
Eine eigene Streitfrage: Wann wird der Challenger zum neuen Champion? Direkt bei 100%? Dann fehlt der Rollback-Anker. Erst nach Tagen Stabilität? Dann laufen Shadow-Vergleiche gegen einen veralteten Champion. Eine pragmatische Default-Regel: Promotion 7 Tage nach 100%, sofern die Steady-State-Metriken in Toleranz bleiben - kürzer bei reinen Prompt-Edits, länger bei Modell-Switches.
Rollback: hart, nicht weich
Rollback-Trigger gehören als harte Governance-Boundaries definiert, nicht als subjektive Qualitätsurteile. Eval-Pass-Rate unter X Prozent: Rollback. Halluzinationsrate über Y: Rollback. Token-Kosten-Regression über Z: Rollback. Keine Diskussion, keine “aber das war ein Ausreißer”-Debatte zur Laufzeit.
Dazu der Kill Switch als manueller Notausschalter. Für den Fall, den keine Metrik gefangen hat - weil er neu ist.
Wer Rollback als Diskussion definiert, hat kein Rollback. Er hat eine Meeting-Einladung.
Wer darf was?
| Rolle | Pre-Merge Review | Shadow-Analyse | Canary-Promote | Rollback | Kill Switch |
|---|---|---|---|---|---|
| Entwickler | ja | ja | intern / Dogfood | bei techn. Regression | bei techn. Regression |
| Produkt | - | ja | kundenseitig | nach Review | - |
| On-Call | - | - | - | jederzeit | jederzeit |
| Compliance / Legal | bei Modell-Switch | bei Policy-Change | - | - | - |
Die Matrix ist kein Dogma. Sie ist ein Anfang. Wichtig ist, dass jede Zeile in einem konkreten Setup beantwortet ist - auch die leeren Zellen.
Approval auf Release-Ebene ist Approval auf Tool-Ebene
Wer “Canary-Promote braucht Human Approval” entwirft, entwirft dasselbe Muster, das in Agent-Architekturen auf Tool-Ebene steht: bevor der Agent eine Aktion ausführt, die Konsequenzen hat, fragt er nach. Release ist Tool-Call, nur eine Ebene höher.

Regulatorischer Kontext: das ist kein Nice-to-have
Der EU AI Act tritt für High-Risk-Systeme unter Annex III am 2. August 2026 in Kraft. Relevant für den Rollout-Prozess sind vor allem Art. 9 und Art. 17.
Art. 9 verlangt ein Risk-Management-System als “a continuous iterative process planned and run throughout the entire lifecycle of a high-risk AI system”. Und: “Testing shall ensure that high-risk AI systems perform consistently for their intended purpose.”
Art. 17 fordert ein Quality-Management-System, das “examination, test and validation procedures to be carried out before, during and after the development” dokumentiert - ausdrücklich auch nach Deployment. Art. 17 muss das Risk-Management aus Art. 9 integrieren, und das Post-Market-Monitoring (Art. 72) ist Teil davon. Art. 72 verlangt dabei nicht nur, Metriken zu sammeln: Auch die Auswertung und die Reaktion darauf müssen dokumentiert sein.
Heißt konkret: Shadow liefert Test-Evidenz vor User-Exposure. Canary mit Gates operationalisiert den “continuous iterative process”. Rollback und Kill Switch sind die konkreten Maßnahmen, um das Rest-Risiko unter der akzeptablen Schwelle zu halten - für das, was trotz aller Gates durchkommt. Continuous Evaluation in Prod speist Post-Market-Monitoring.
Validierungs-Prozeduren in Art. 17 müssen durchgeführt werden, nicht nur dokumentiert: Ein Kill Switch, der nie unter Last getestet wurde, ist eine Annahme. Ein Rollback-GameDay pro Quartal - Switch triggern, Recovery-Zeit messen, Befunde dokumentieren - liefert die Evidenz, die ein Audit nicht durch Code-Reading entscheiden kann.
Konkret: Rollback-GameDay in 60 Minuten
Vorbereitung (Tag vorher):
- Erfolgskriterium festschreiben: Welche Metriken müssen zurück im Soll sein, damit Recovery zählt? Eval-Pass-Rate, Error-Rate, p95/p99-Latenz wieder auf Baseline.
- Stakeholder informieren: Angekündigte Übung, kein Stealth-Test - sonst entstehen Incident-Tickets, die der GameDay selbst verursacht.
- Rollback-Pfad festlegen: Kill Switch (Feature komplett aus), Bundle-Apply (vorheriges Manifest re-applizieren), Tool-Block (nur ein MCP-Tool aus). Pro GameDay einen Pfad.
Durchführung:
- T−5min: Baseline-Snapshot von Eval-Pass-Rate, Error-Rate, p95/p99-Latenz, Token-Kosten.
- T0: Trigger setzen. Stoppuhr.
- T+1, +5, +15min: Metriken erneut messen. Recovery-Zeit ist der Punkt, ab dem die Erfolgskriterien stabil halten - nicht der erste Touch der Schwelle.
Auswertung:
- Recovery-Zeit als harte Zahl ins Quartals-Review.
- Was hat länger gedauert als gedacht? Webhook-Verzögerung, DNS-TTL, Cache-Invalidation, Provider-Latenz beim Flag-Update - genau die Befunde, die im Normalbetrieb unsichtbar bleiben.
- Findings als Tickets, nicht als Slack-Thread - sonst war der GameDay reine Show.
Anti-Pattern: Drill in der ruhigen Stunde. Wenn der Switch bei drei Requests pro Minute glatt durchläuft, sagt das wenig über den realen Incident-Fall. GameDay zur Peak-Zeit, sonst kein belastbares Ergebnis.
Wer Shadow, Canary und Rollback baut, baut nebenbei die Evidenz, die der EU AI Act fordert. Wer das nicht baut, hat ab 2. August 2026 ein Problem - nicht nur ein Qualitäts-, sondern ein Compliance-Problem.
Welche Artikel der Rollout-Prozess abdeckt
- Art. 9 - Risk Management System: kontinuierlicher iterativer Prozess über den Lebenszyklus. Abgedeckt durch Shadow-Evidenz, Canary-Gates und definierte Rollback-Trigger.
- Art. 12 - Record-keeping / Logs: automatische Aufzeichnung relevanter Ereignisse. Abgedeckt durch Observability-Traces - der Traceability-Stack aus dem vorherigen Post liefert genau das.
- Art. 14 - Human Oversight: wirksame Aufsicht durch Menschen. Abgedeckt durch Approvals auf Release-Ebene (Promotion) und auf Tool-Ebene (Human-in-the-Loop in Agent-Flows).
- Art. 17 - Quality Management System: dokumentierte Test- und Validierungs-Prozeduren vor, während und nach der Entwicklung. Integriert Art. 9.
- Art. 72 - Post-Market Monitoring: kontinuierliche Überwachung der Performance in Produktion. Abgedeckt durch Continuous Evaluation - Sampling-basierte Auswertung von Prod-Traces.
Wer Canary und Rollback baut, baut parallel Compliance-Nachweis. Der EU AI Act verlangt genau diesen Prozess - er ist kein zusätzlicher Aufwand, er ist der eigentliche Contract.
Typische Gegenargumente
Gegen einen so aufgebauten Rollout-Prozess kommen ein paar wiederkehrende Einwände. Die meisten sind berechtigt - aber sie führen seltener zu “brauchen wir nicht” als zu “brauchen wir kleiner”. Fünf, die mir typischerweise begegnen:
“Wir sind zu klein für so einen Prozess”
Dann bau die kleine Version. Ein Pre-Merge-Eval-Gate plus ein Kill Switch ist das Minimum, und beides lässt sich an einem Nachmittag aufsetzen. Alles andere - Shadow, Canary, Segment-Routing - kommt dazu, wenn der Blast Radius wächst. Rollout-Disziplin skaliert mit dem Risiko, nicht mit dem Org-Chart.
“Shadow Runs verdoppeln unsere LLM-Kosten”
Stimmt - wenn wir Full Traffic shadowen. Deshalb läuft Shadow auf Sample, nicht auf 100%. Die konkrete Sample-Größe ist in keiner der Quellen, die ich dazu gelesen habe, belastbar dokumentiert - also keine Zahl erfunden. Das ist eine Entscheidung, die jedes Team selbst trifft. Was wir aber sagen können: Shadow ist ein bewusstes Investment, keine Gratis-Funktion. Und die Kosten einer unentdeckten stochastischen Regression, die bei echten Nutzern einschlägt, sind fast immer höher als ein paar Tage erhöhter Token-Verbrauch.
“Unser Traffic ist zu gering für Canary”
Stimmt für den klassischen User-Bucketing-Canary. 5% von 50 Tages-Usern sind zwei bis drei Requests pro Tag - statistisch nichts. Aber Canary muss nicht heißen, dass echte User die neue Version sehen. Drei Alternativen ohne Produktions-Volume:
- Interner Canary auf Mitarbeiter-Traffic
- Synthetic Traffic aus kuratierten Prompt-Sets
- Shadow Replay alter Produktions-Traces gegen den Challenger
Selten ausgeschöpft, fast nie kombiniert.
“Feature Flags für AI sind Overkill”
Feature Flags sind nicht Overkill. Sie sind die billigste Form des Rollbacks, die wir haben. Wer ohne Flag deployt, hat im Incident nur eine Option: Hotfix-Deploy unter Zeitdruck, während der Agent weiter Kunden-Tickets falsch beantwortet. Mit Flag sind es drei Klicks auf 0%. Das LaunchDarkly-Pattern für AI-Features ist nicht kompliziert: Metrik-Threshold überschritten - Webhook - Flag auf 0%. Mehr braucht ein Kill Switch nicht, um seinen Job zu tun.
“Unsere Evals sind gut genug, wir brauchen kein Shadow”
Evals testen gegen ein kuratiertes Set. Produktion hat eine Long-Tail-Verteilung, die kein Eval-Set vollständig abdeckt. Das ist kein Versagen der Evals - das ist die Definition von Long Tail. Shadow und Evals sind komplementär, nicht konkurrierend:
Evals beantworten “Funktionieren meine bekannten Fälle?”. Shadow beantwortet “Funktionieren die Fälle, die ich noch nicht kenne?”.
Wer nur eines von beiden baut, hat eine Lücke. Die Frage ist nur, welche.
Rollout ist nicht optional, er ist Teil des Contracts
Evals im PR beantworten eine Frage: “Ist der Code nicht kaputt?” Rollout-Disziplin beantwortet eine andere: “Ist das System unter echtem Traffic nicht kaputt?” Beide Fragen müssen beantwortbar sein. Klassische Software hat diesen Unterschied längst verstanden - bei AI-Features zieht die Praxis erst nach.
Teams, die bereits Observability auf Stufe 2 oder 3 haben, können Shadow und Canary ohne Neubau einführen. Das Reifegradmodell aus dem Observability-Post ist die Voraussetzung, nicht die Alternative. Wer keine Traces, keine Prompt-Versionen und keine Cost-Metriken hat, kann auch keinen Guarded Rollout fahren.
Der wichtigste Takeaway: Jede Art von Änderung - Code, Prompt, Modell, Tool-Description, RAG-Index - muss eine Rollout-Stufe durchlaufen. “Prompt ist ja nur Text” ist kein Freibrief. “Tool-Description ist ja nur Metadata” auch nicht.

Und dann gibt es noch den nächsten Schritt, der sich daraus ergibt und der hier nicht mehr hineinpasst: Produktions-Incidents als Test-Dataset ernstnehmen. Von Post-Mortem zur Eval. Aber das ist ein anderer Post.
Ein AI-Feature in Produktion zu nehmen heißt nicht nur, es live zu schalten. Es heißt, jederzeit erklären zu können, warum es heute anders antwortet als gestern - und es jederzeit zurücknehmen zu können.